Where is the acceleration of science?
Author: James Brand
Date: 2026-06-10
TL;DR: So far, the biggest impact of LLMs on (open, academic) scientific production might be creating more research about LLMs. I downloaded a bunch of papers and abstracts from arXiv and found:
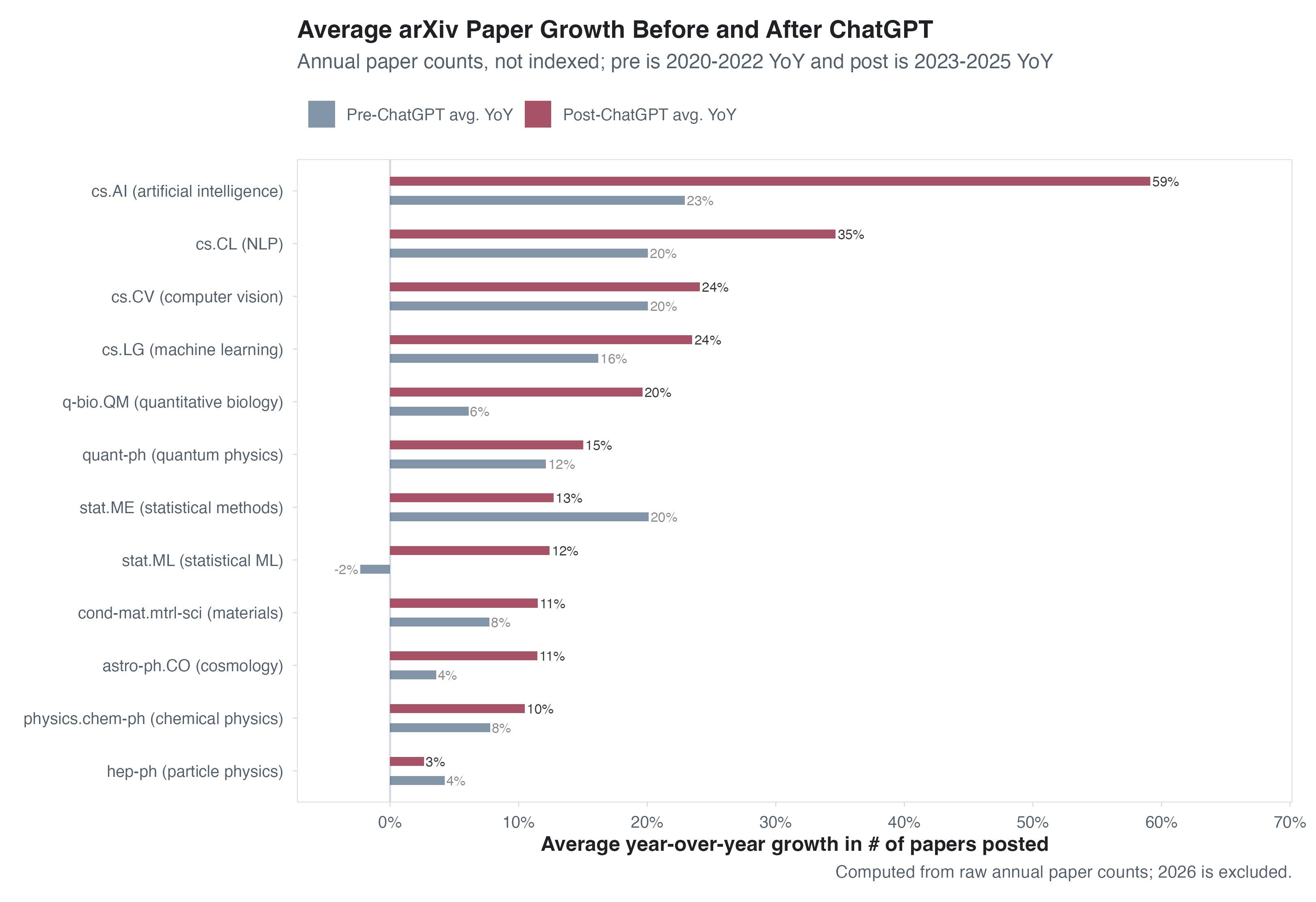
- The number of papers being produced per year has grown fastest in
cs.AI, which has also seen more homogeneity in abstracts and titles since November 2022 and a stark increase in mentions of LLMs (and reduction of references to other ML/deep learning terms)- Math theorems have not seen a reduction in errors since 2022
- Papers do not seem to have more results, measured by figures, tables, or formal results (theorems/lemmas)
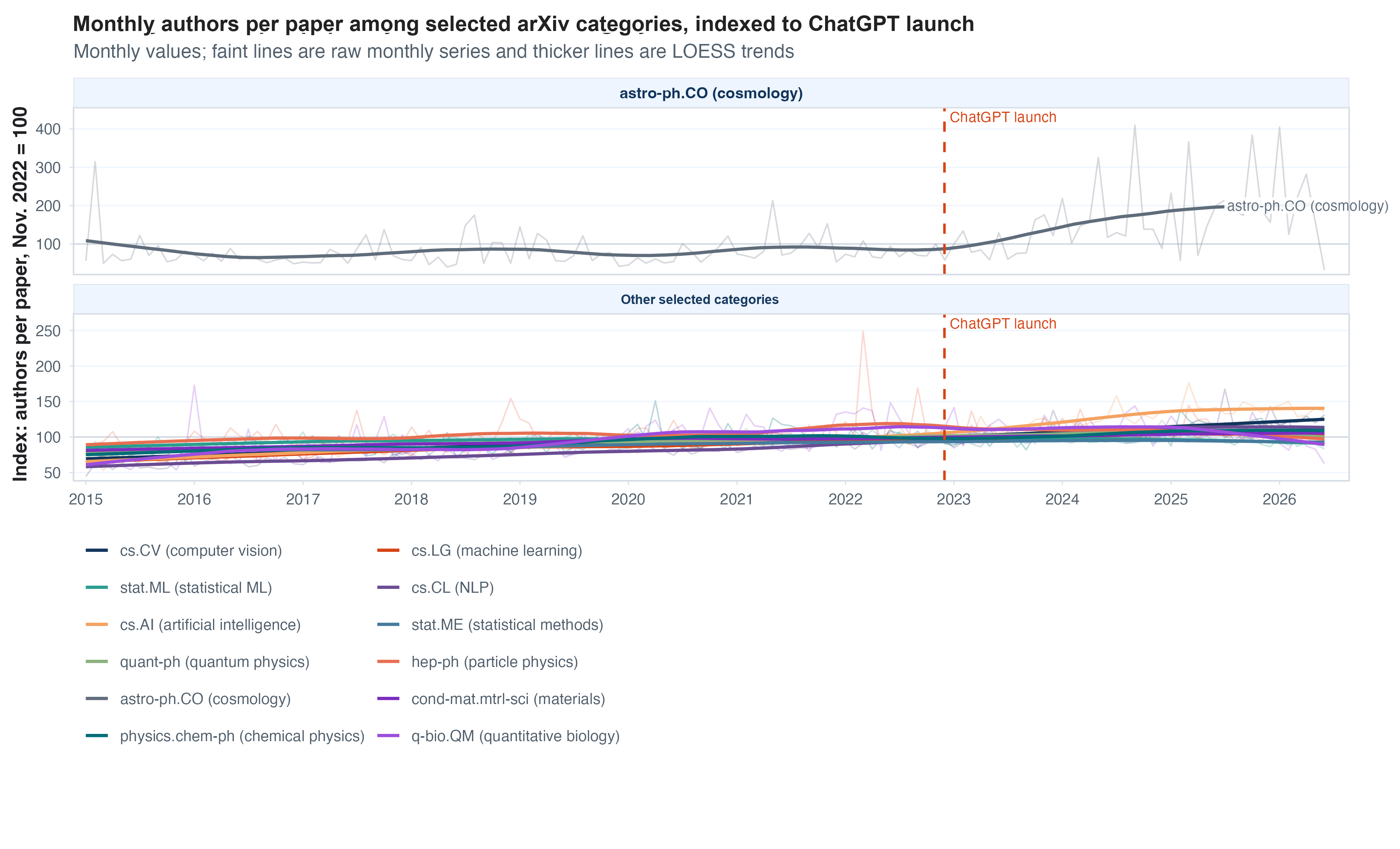
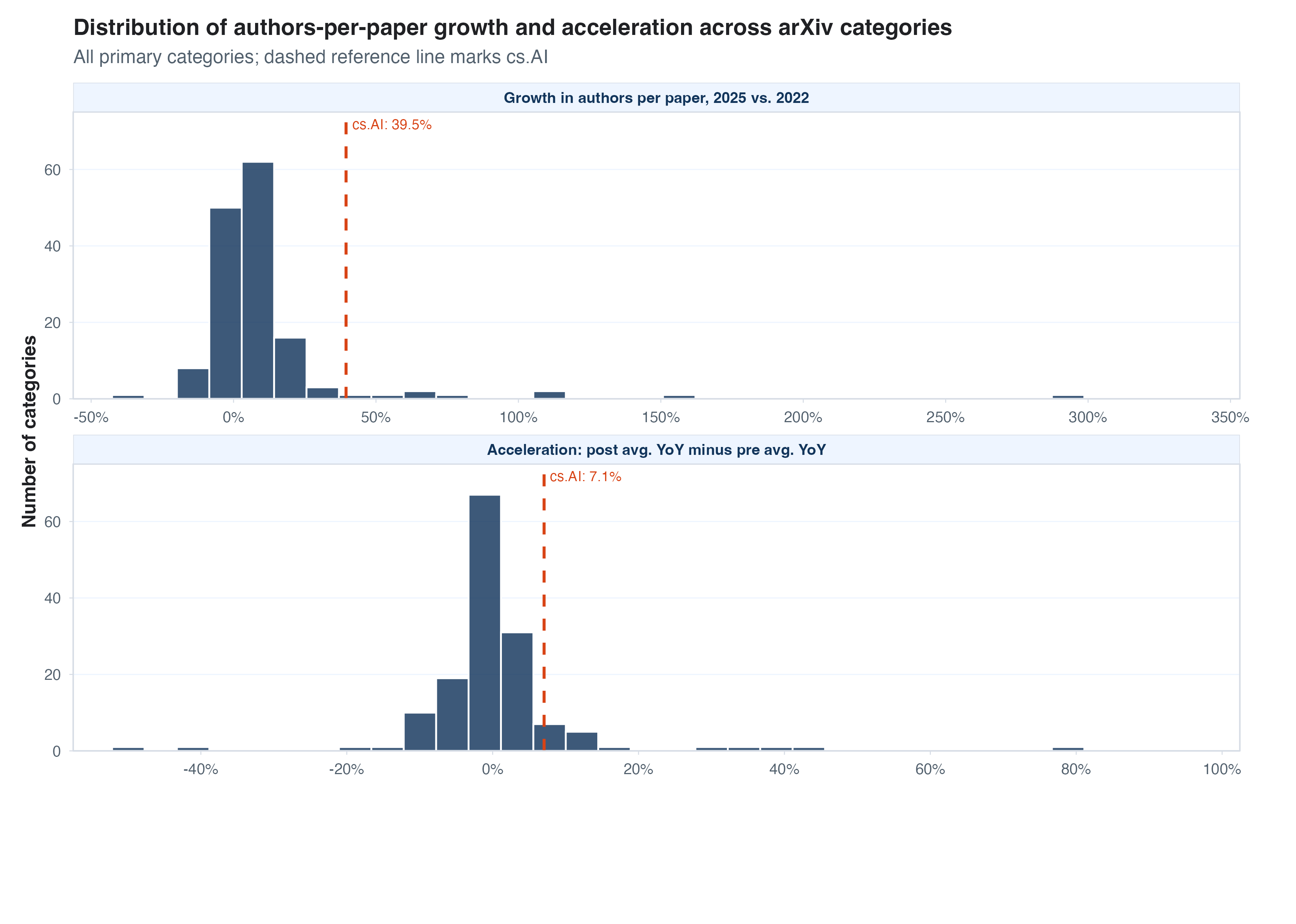
- Research output per author has increased since Nov 2022, but mostly through the rise of larger coauthorship teams
Motivation
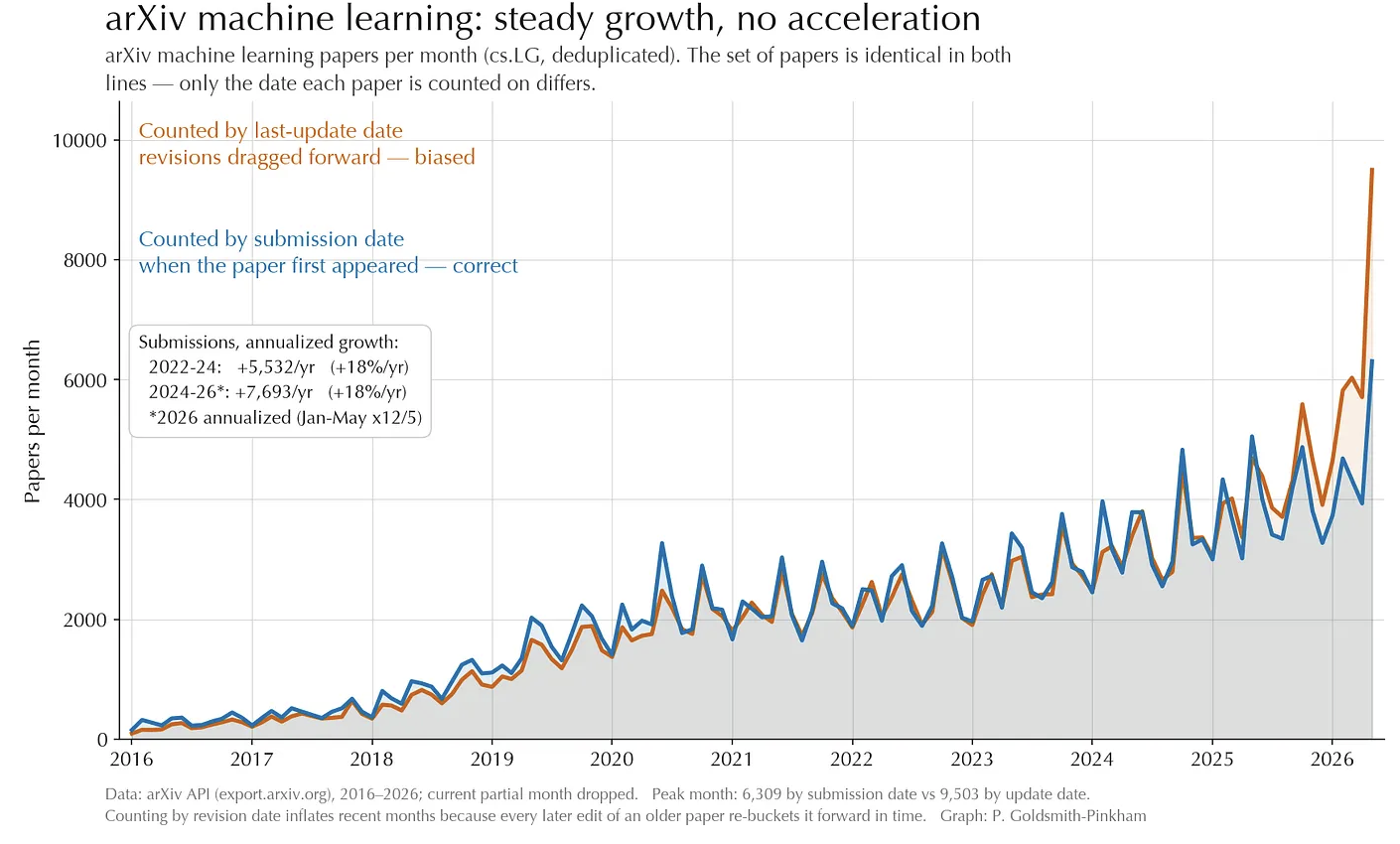
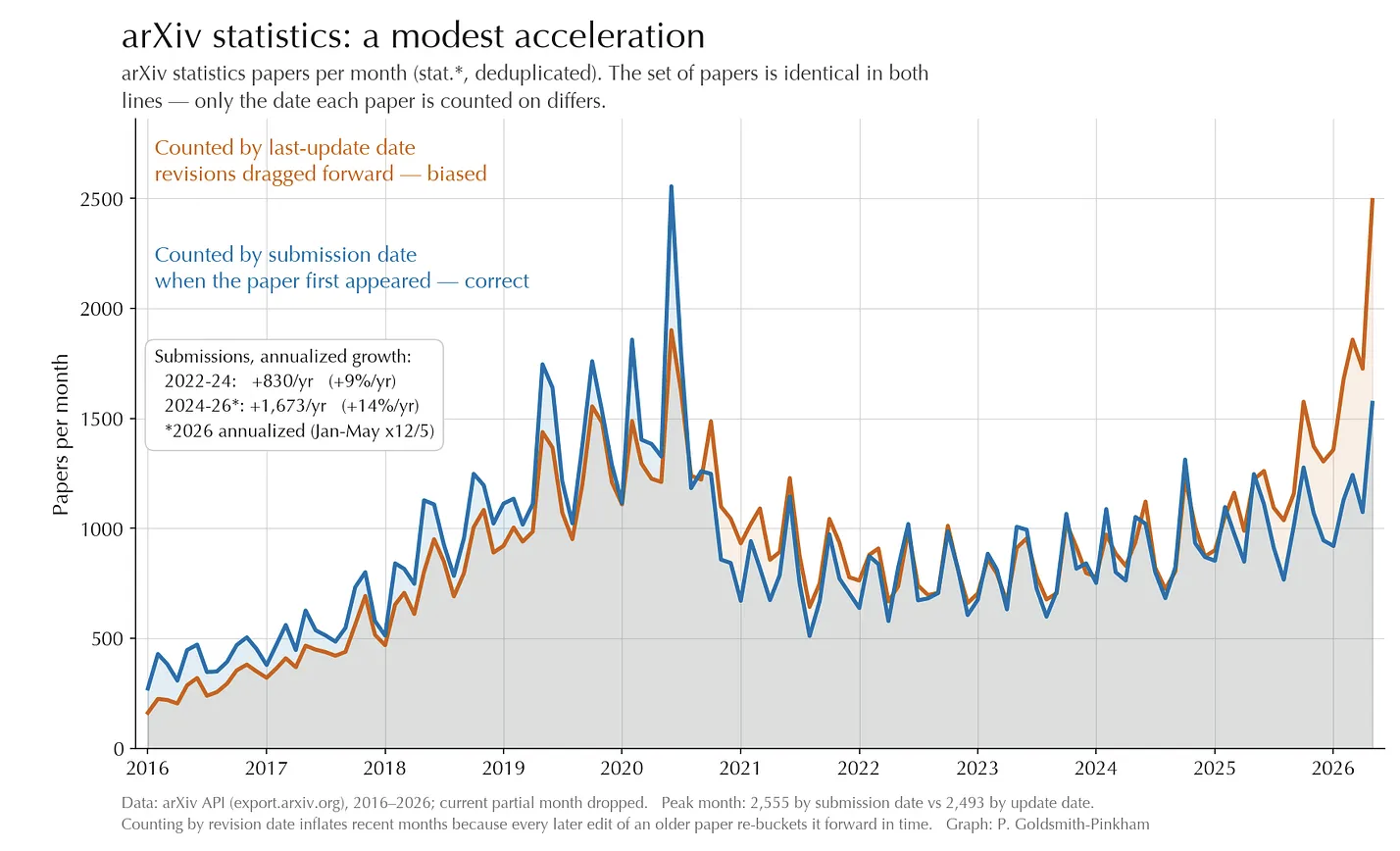
This post was inspired by two things. First, this post by Paul Goldsmith-Pinkham showed that we haven’t really seen an explosion of new research on websites like arXiv, SSRN, etc., at least in the field of economics. So, when we look at the “final” unit of production of researchers, there isn’t a massive increase in output yet even with all of the hype around using AI to accelerate science.
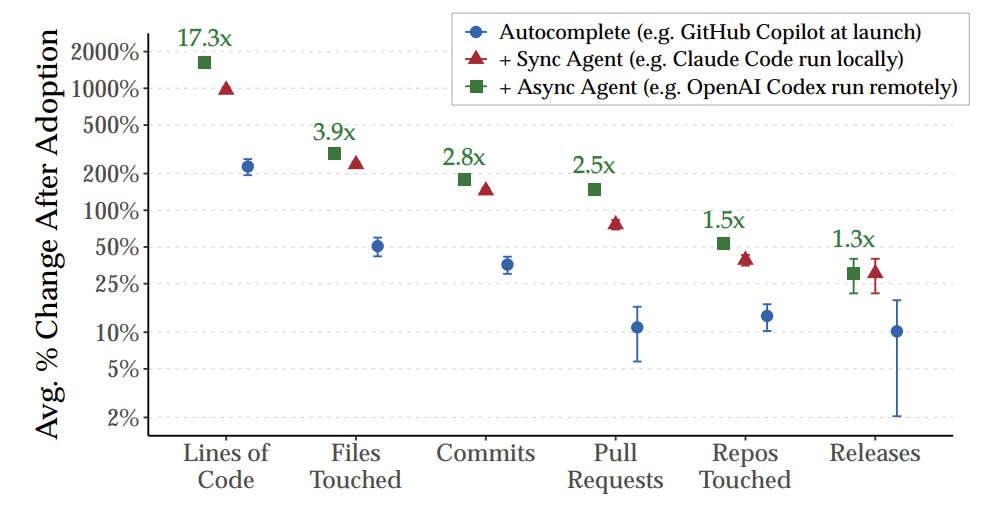
Second, this paper by Mert Demirer, Leon Musolff, and Liyuan Yang provided some fantastic estimates of the impact of AI on different stages of software production. Their key figure below shows that, although AI use increases the number of lines of code by more than an order of magnitude, the impact on the number of (GitHub) releases is far more muted. Of course, as others have noted, even releases are often not the end of the production process, so the impact on new products and features may be even smaller. So, when we think about AI’s role in any production process, we need to study its impact on both the final output and intermediate components.
Together, these points raise two questions:
- Are there any fields which have seen an “explosion” of new research (more papers, more results per paper)?
- Is AI improving scientific productivity within a paper by increasing the quantity or quality of new results, the originality of ideas, or replicability?
Data
Below, I’ll walk through a bunch of heavily Codex-augmented attempts to test some of these possibilities. I downloaded around 70,000 papers from arXiv as well as all metadata from arXiv from the past 20 years. I chose three (non-mutually exclusive) ways to cut/group papers: a “Theory” cut that includes computer science and math, economics and finance, and a “CS/AI + natural science” cut. Some natural science categories that include theoretical components can show up in the first and third groups.1 Papers were randomly sampled within selected categories each year.
| Dataset | What it contains | Papers covered | arXiv categories included |
|---|---|---|---|
| Full metadata | arXiv metadata (IDs, dates, categories, titles, authors, abstracts, links) | Essentially all arXiv papers in the extraction window (about the past 20 years) | all |
| Embeddings | OpenAI text-embedding-3-small vectors for titles and
abstracts |
About 380,000 papers from 2015-2025 | all |
| Full text | Parsed PDF body text plus extracted figure/table/theorem/repos | About 70,000 papers (subsampled by category-year) | Theory (math, CS, etc.) set + Econ/Finance + CS/AI and natural science set (as defined in Footnote 1) |
Has research production accelerated?
First, let’s extend Paul’s graphs above to look at a broader set of fields and see whether simple measures of output, within author and within paper, have increased.
Total number of papers
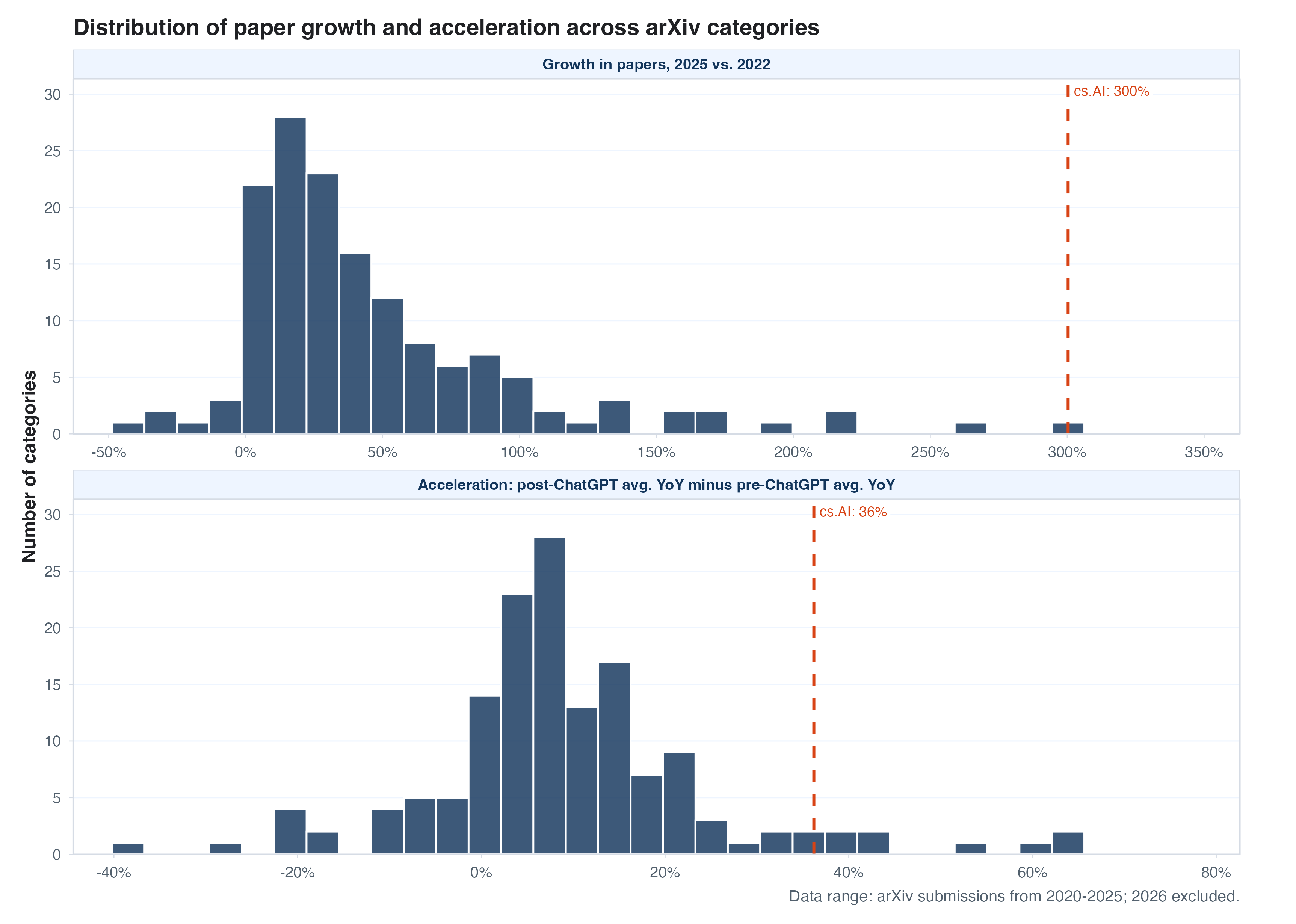
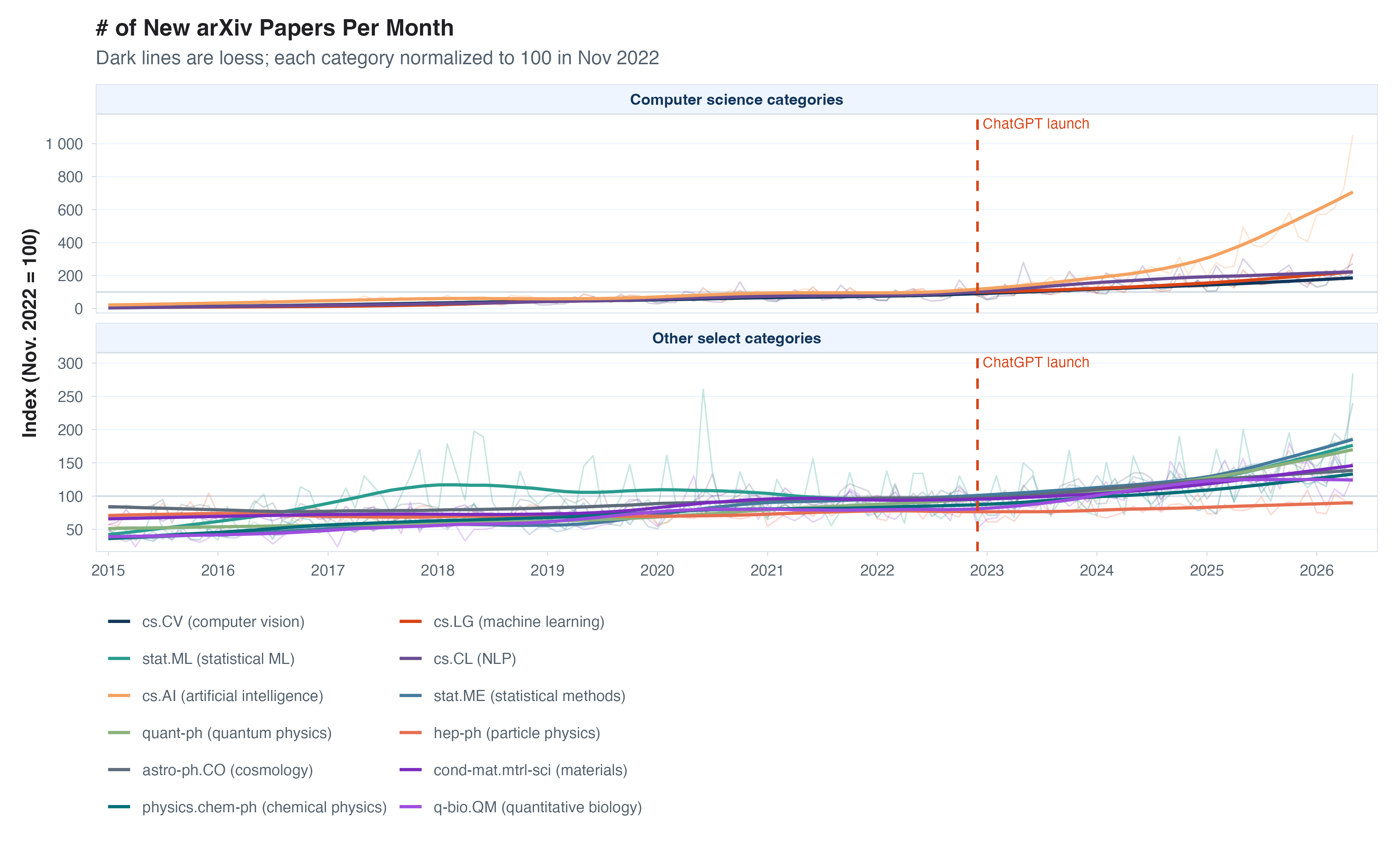
Starting with raw counts of arXiv-posted papers, the evidence that
there’s been a big acceleration in the number of papers being posted to
arXiv is indeed pretty weak. As you can see in the left graph below,
output growth in the cs.AI category on arXiv is a major
outlier among large categories, having more than quadrupled in recent
years. For everything else, we’ve got a bit of a Rorschach test. Paper
production has accelerated a little on average (right graph shows
distribution over all categories), but if that’s happening it’s both
relatively concentrated and relatively recent.
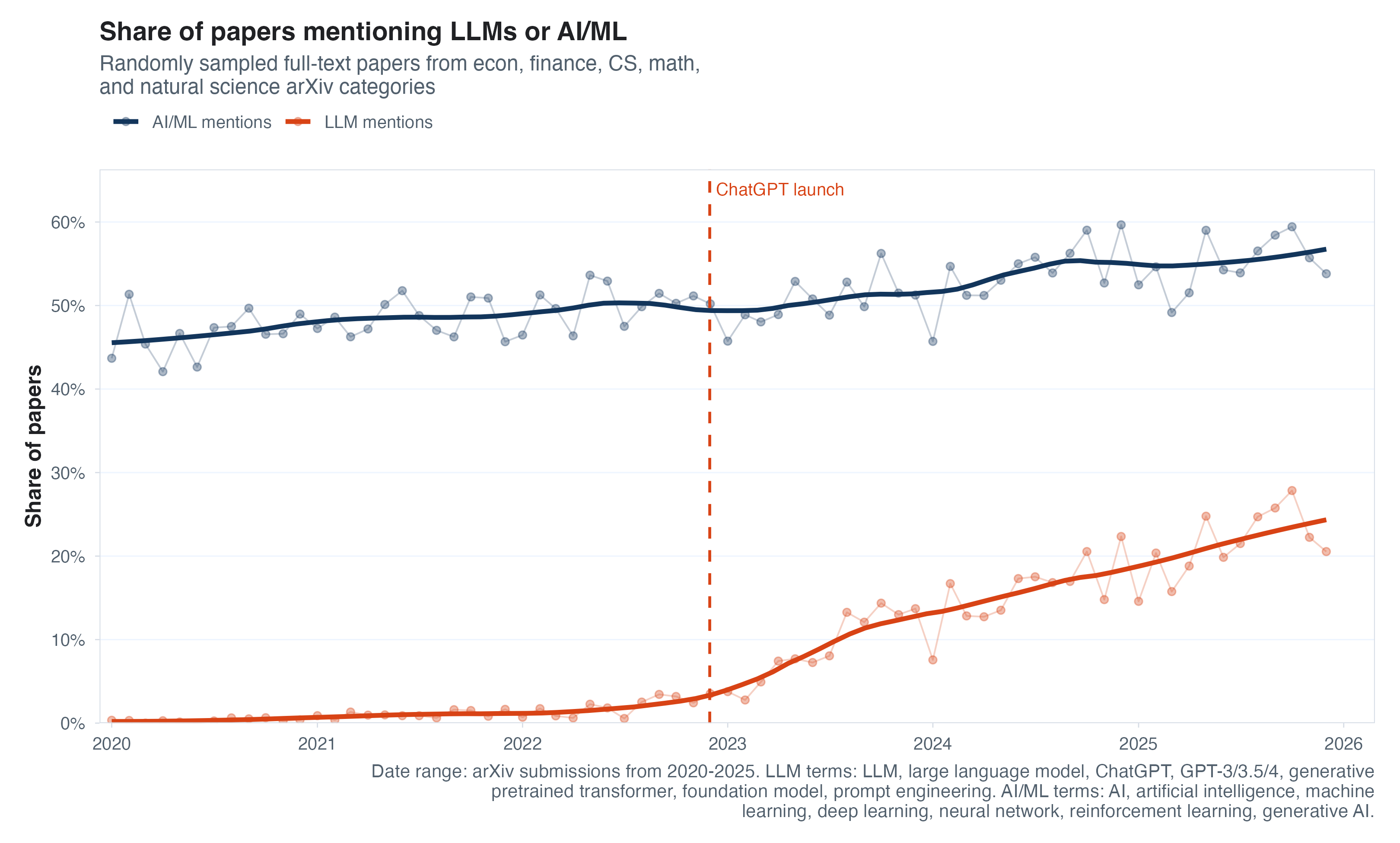
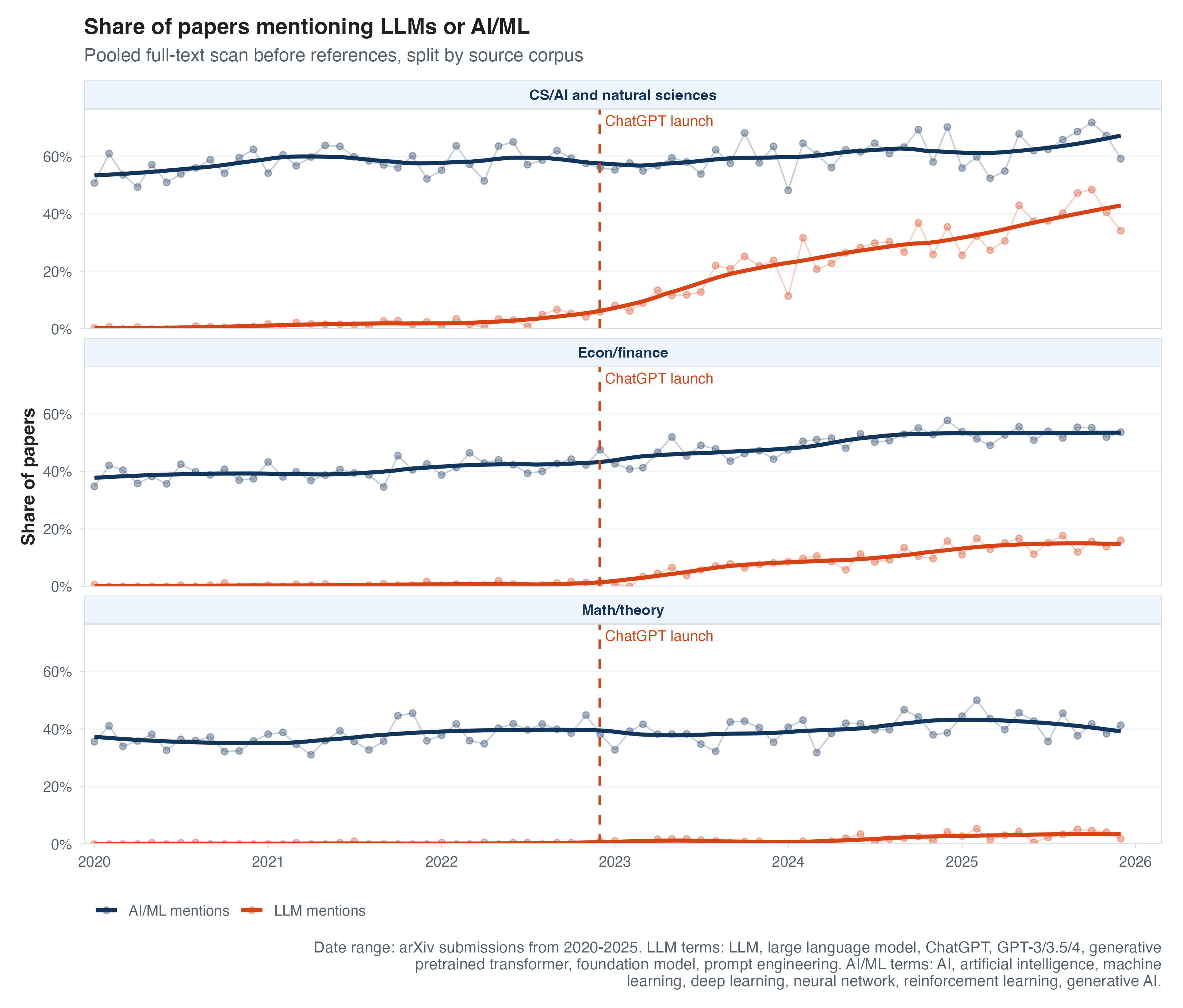
Funny enough, this subtle acceleration is in contrast to an immediate explosion of LLM-related keyword mentions in papers. Below I show the rates of “AI/ML” (i.e., more old-school ML methods) keywords over time vs. more LLM-specific keywords, among the full-text papers I downloaded. ML mentions have grown basically linearly, while LLM mentions have grown from nothing to a huge fraction of papers. The hidden extra plots below show that this is strongest in CS, where more than 40% of the papers I sampled mention LLMs or an adjacent phrase.
Extra plots
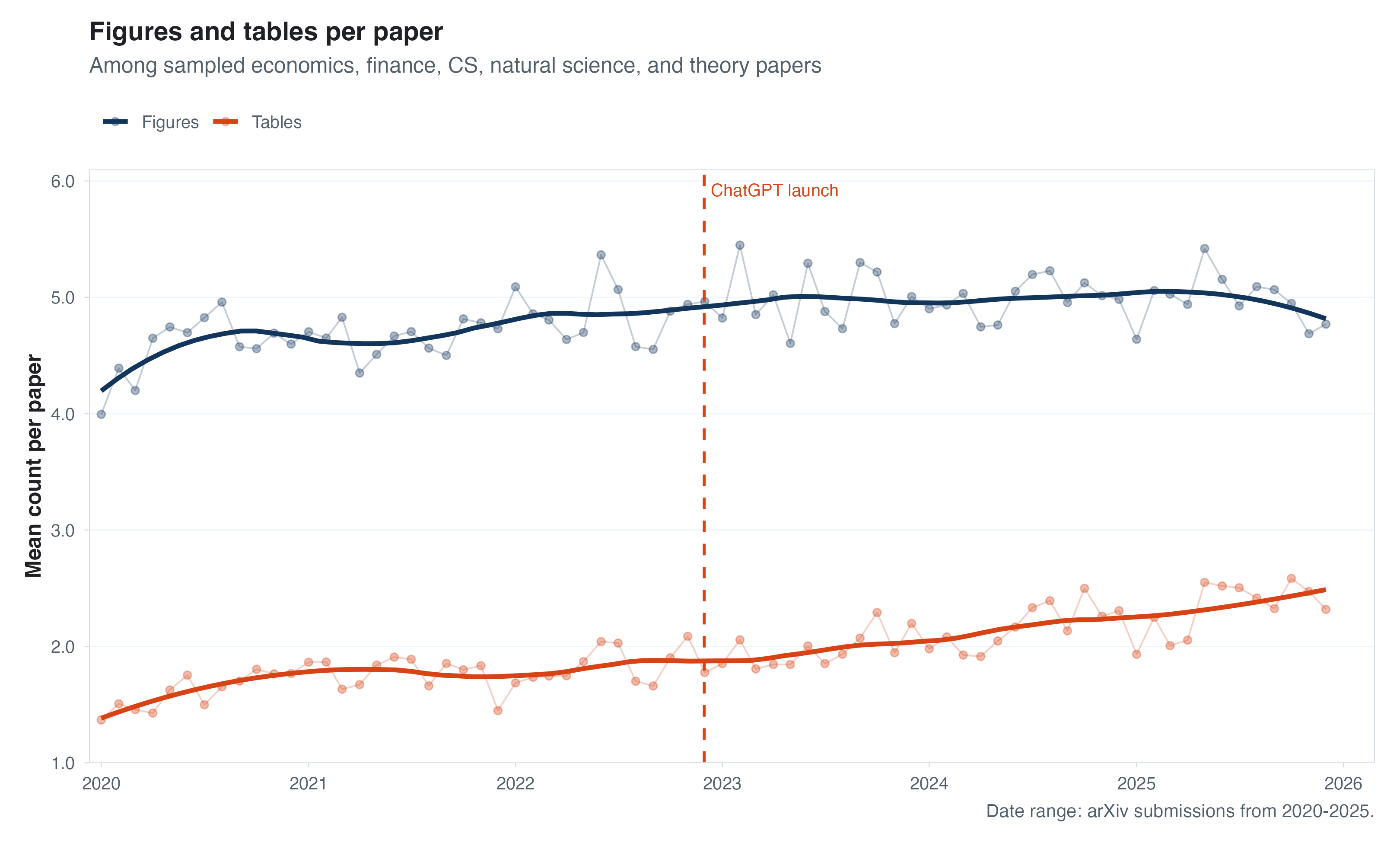
Output per author and per paper
Another way to think about output is to fix a productive unit, either authors, as producers, or papers as a unit of research output, and study efficiencies within that unit. Two examples: (1) are authors who write at least one paper in a given year writing more papers now? and (2) do papers have more figures or more tables in them, as a proxy for more “results”? I look at both of these below. If we look at the number of papers per “active” author (those with at least one paper each year), we see pretty smooth growth over time and no real kink or jump since late 2022.
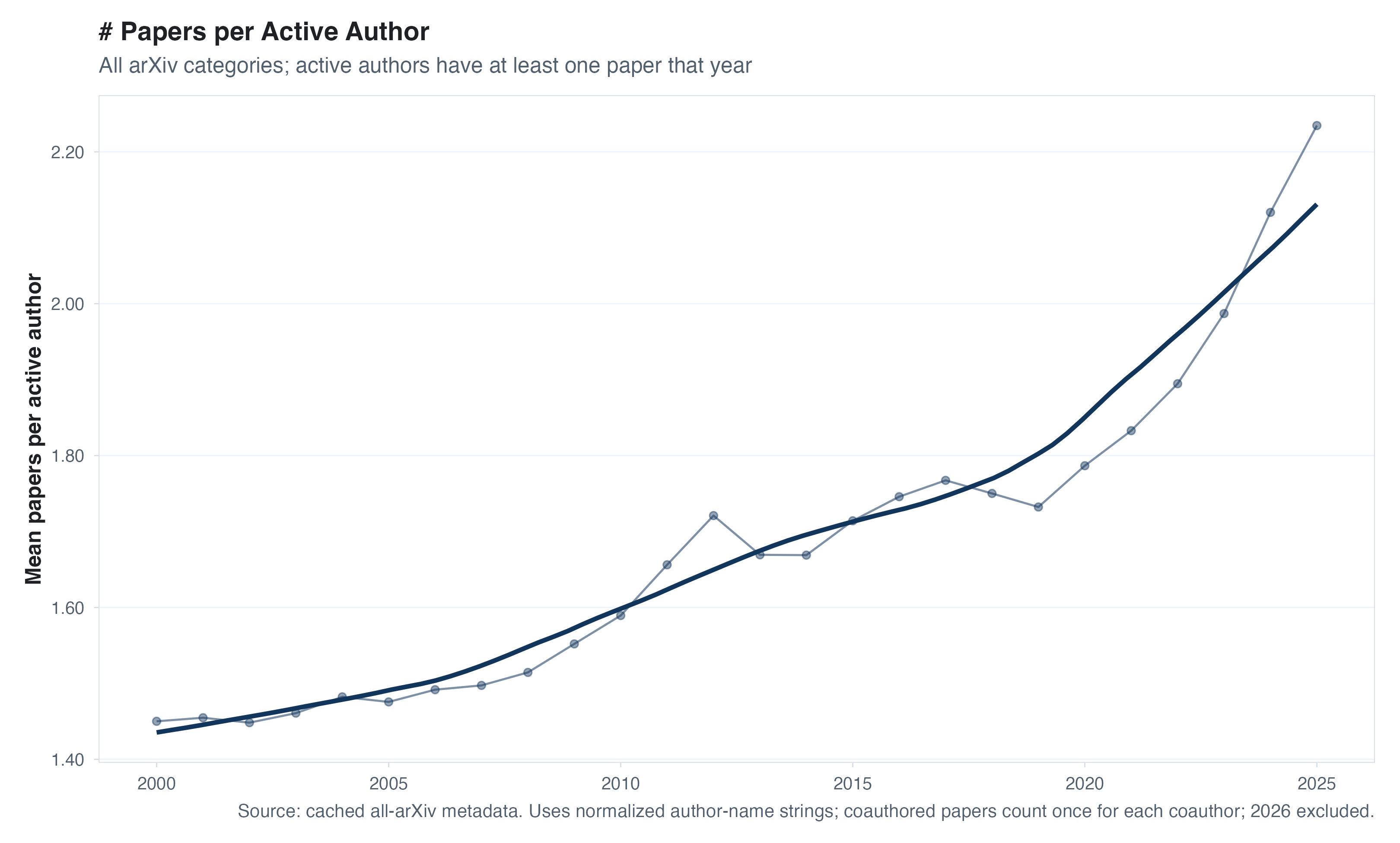
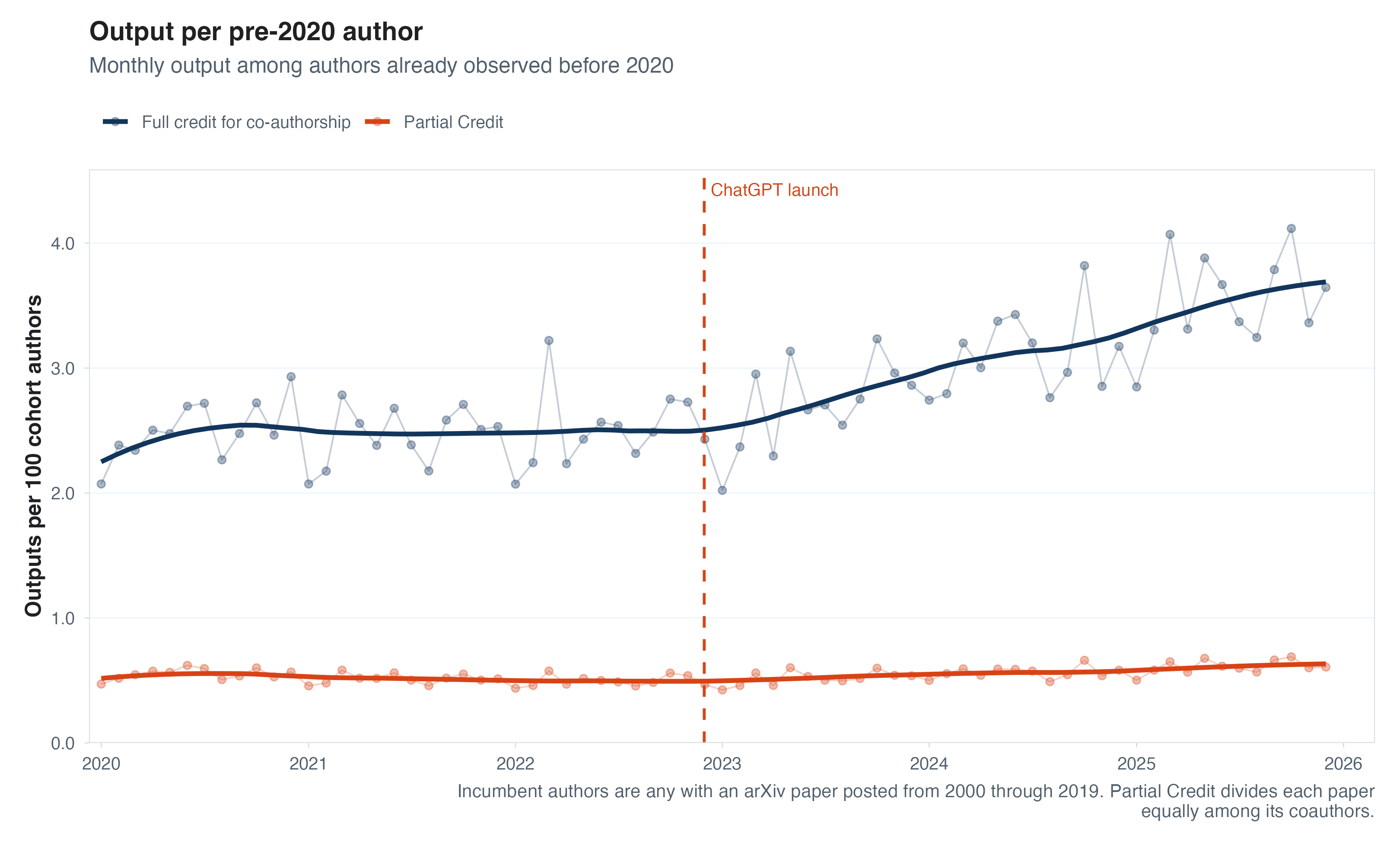
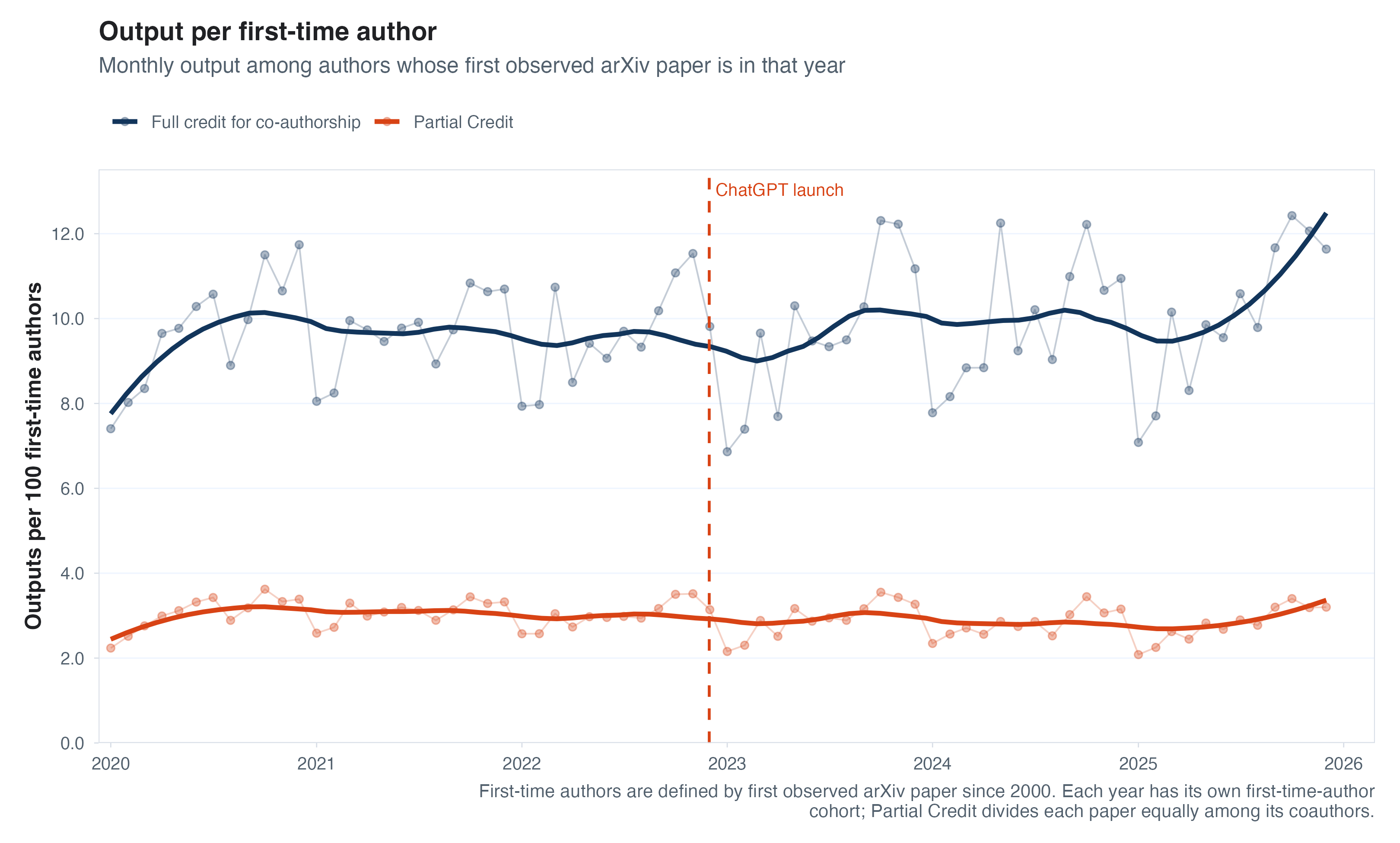
I only had time to be so careful here, but one thing that worried me above is that the composition of “active” authors each year is changing over time. As arXiv grows in popularity, maybe new authors start posting but are much less attached to academia/research and produce fewer, or smaller, papers. Or, maybe the new entrants are AI-native researchers who can crank out knowledge quickly. The other thing I worried about is that the number of authors per paper is growing over time, making how we account for “papers per author” a choice we have to make. So one quick check we can do is to see whether any trends in output per author change if we compare these productivity trends between authors who had a paper on arXiv before 2020 (the metadata I downloaded starts in 2000) with new authors each year.
It turns out both of these splits do matter. Focusing on a fixed set of authors with papers on arXiv before 2020, we see a pretty stark uptick in output per year if we count output as “how many papers does an author have their name on?” If we instead assign credit proportional to the number of authors on each paper, we see a lower and pretty flat line. Looking at new arXiv authors each year is also informative, because there really isn’t much of a trend there. Aren’t the young/new researchers supposed to be all about AI? New authors produce a lot more than the average author (naturally, because we’re conditioning on activity) but no real change in the post-LLM world.
Extra plots
Replications/repos
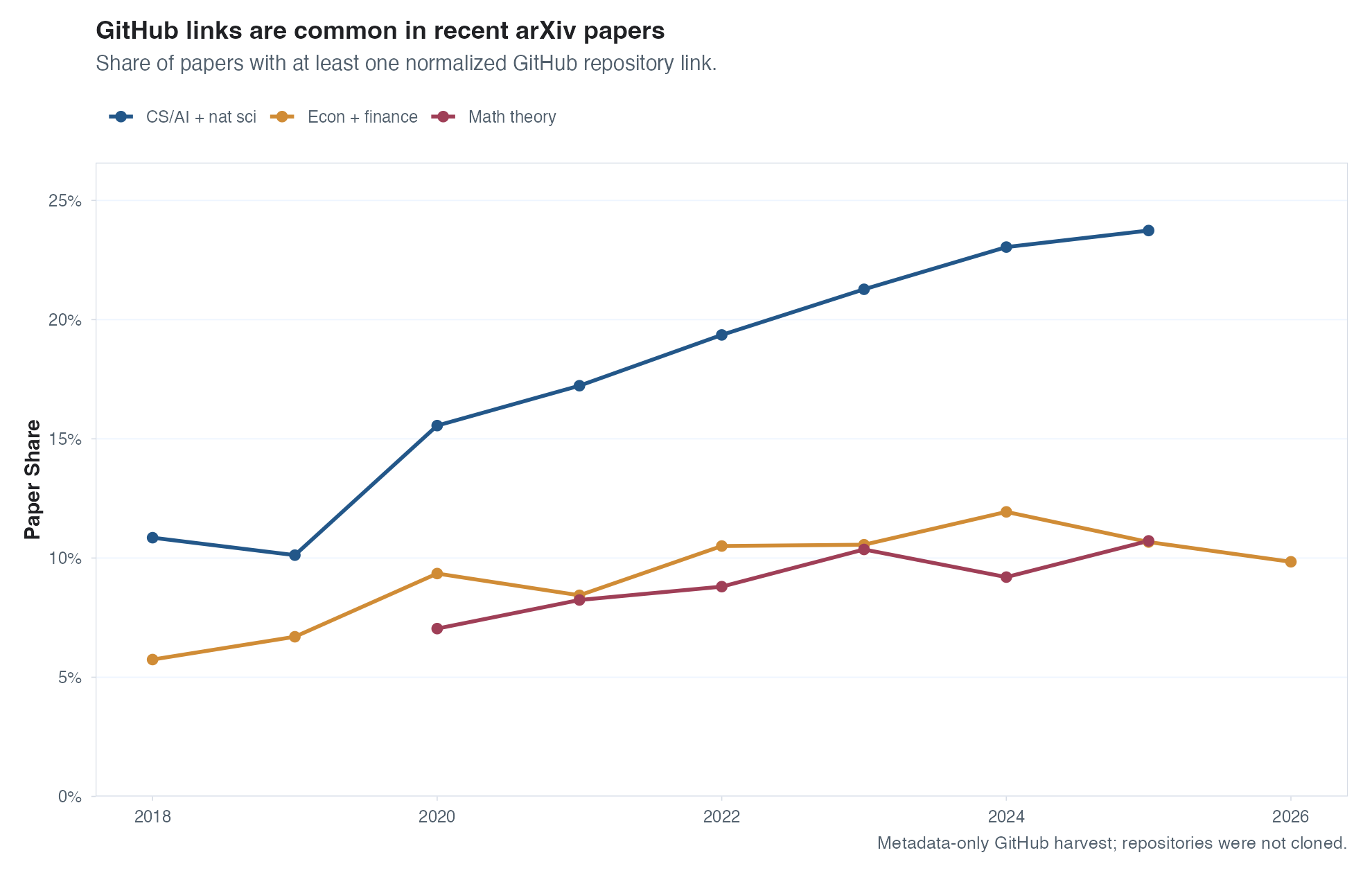
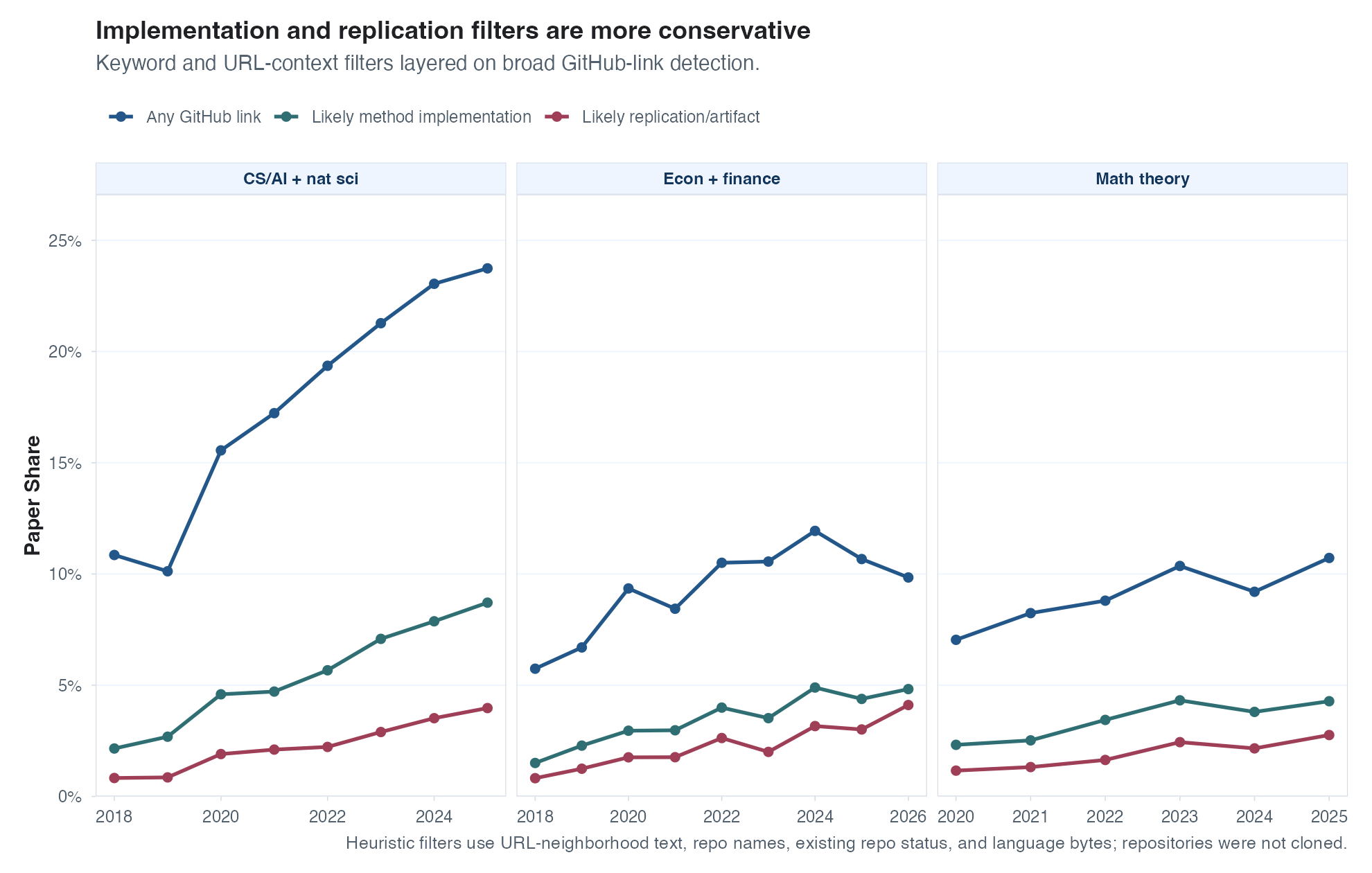
Now let’s see whether papers are more easily replicable, which I would view as another good step for science. Here I used some simple keyword checks to detect whether papers include a link to some kind of code repo.2 There are a bunch of false positives here I’m sure (e.g., the average paper with one GitHub link in my sample has ~1.5 links) but as long as false positive rates aren’t changing too much over time, maybe we can still learn something. The plot below shows the top-level share of sampled papers with at least one repo link. The share of papers with repos is certainly increasing, especially in CS and natural sciences, but I don’t see any kind of major shift starting after ChatGPT was launched. This is pretty shocking to me; I would have bet on good odds that the number of code repositories linked to papers had increased enough that it would be visible even from a top-line graph like this.
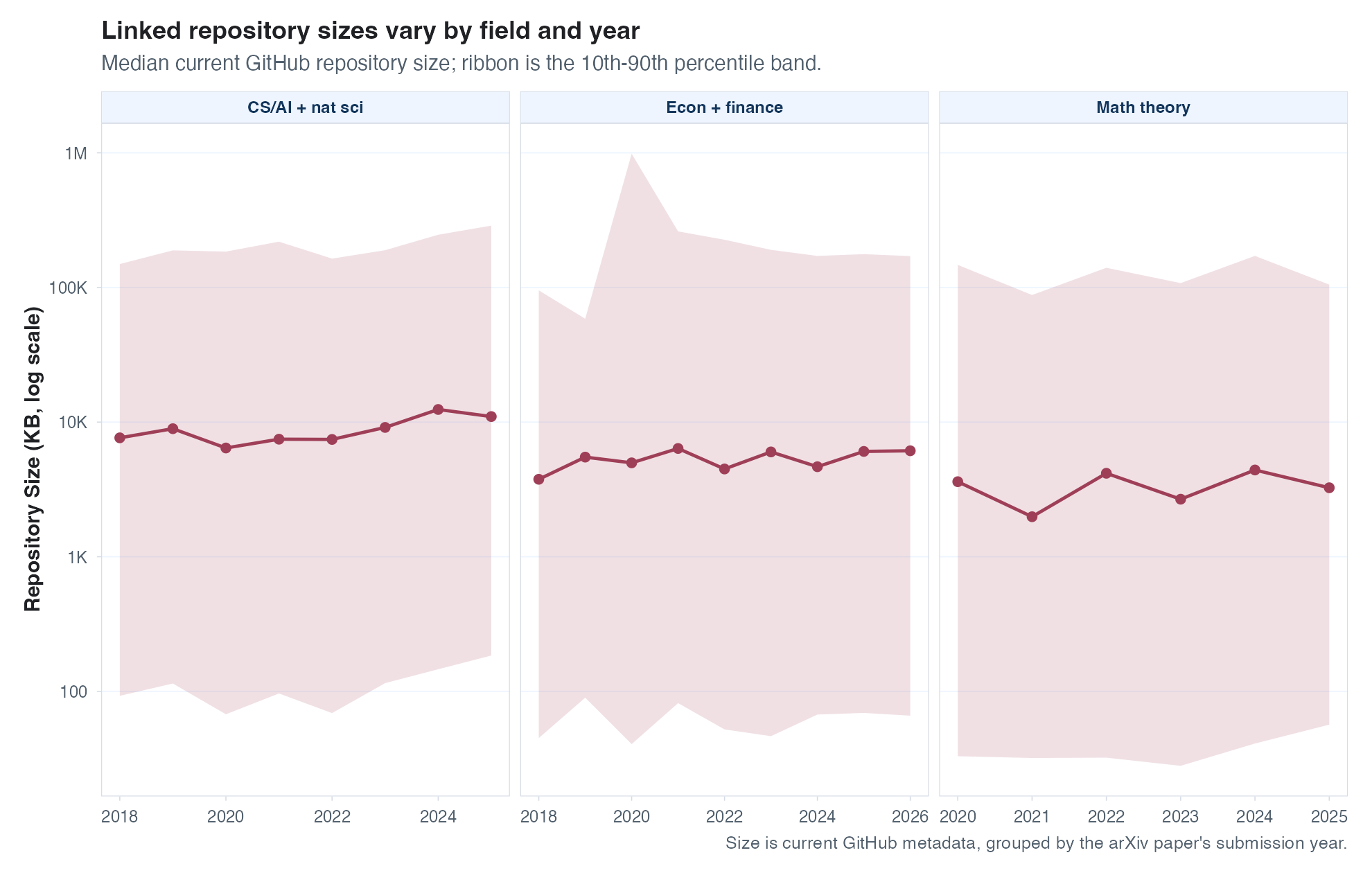
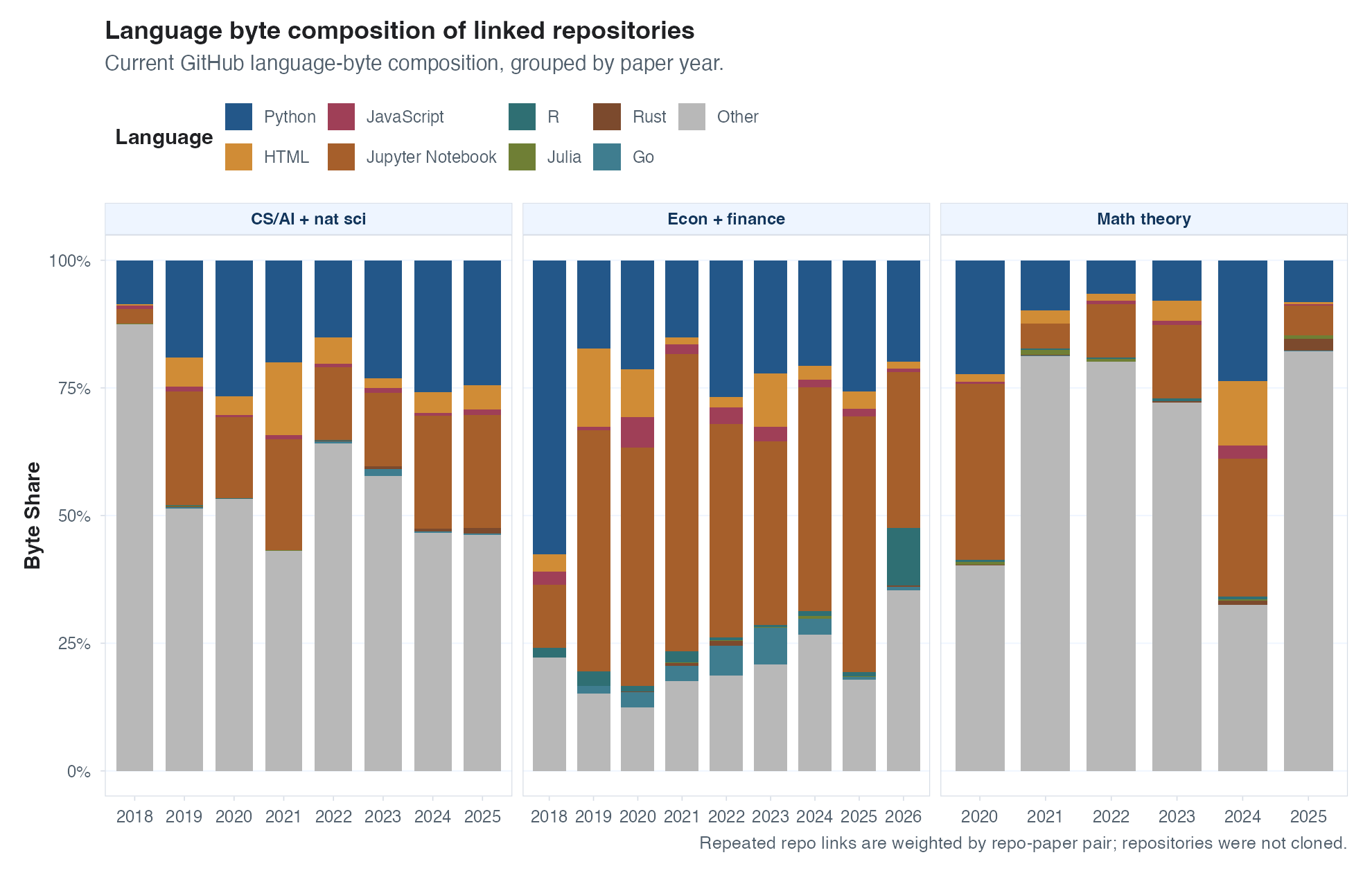
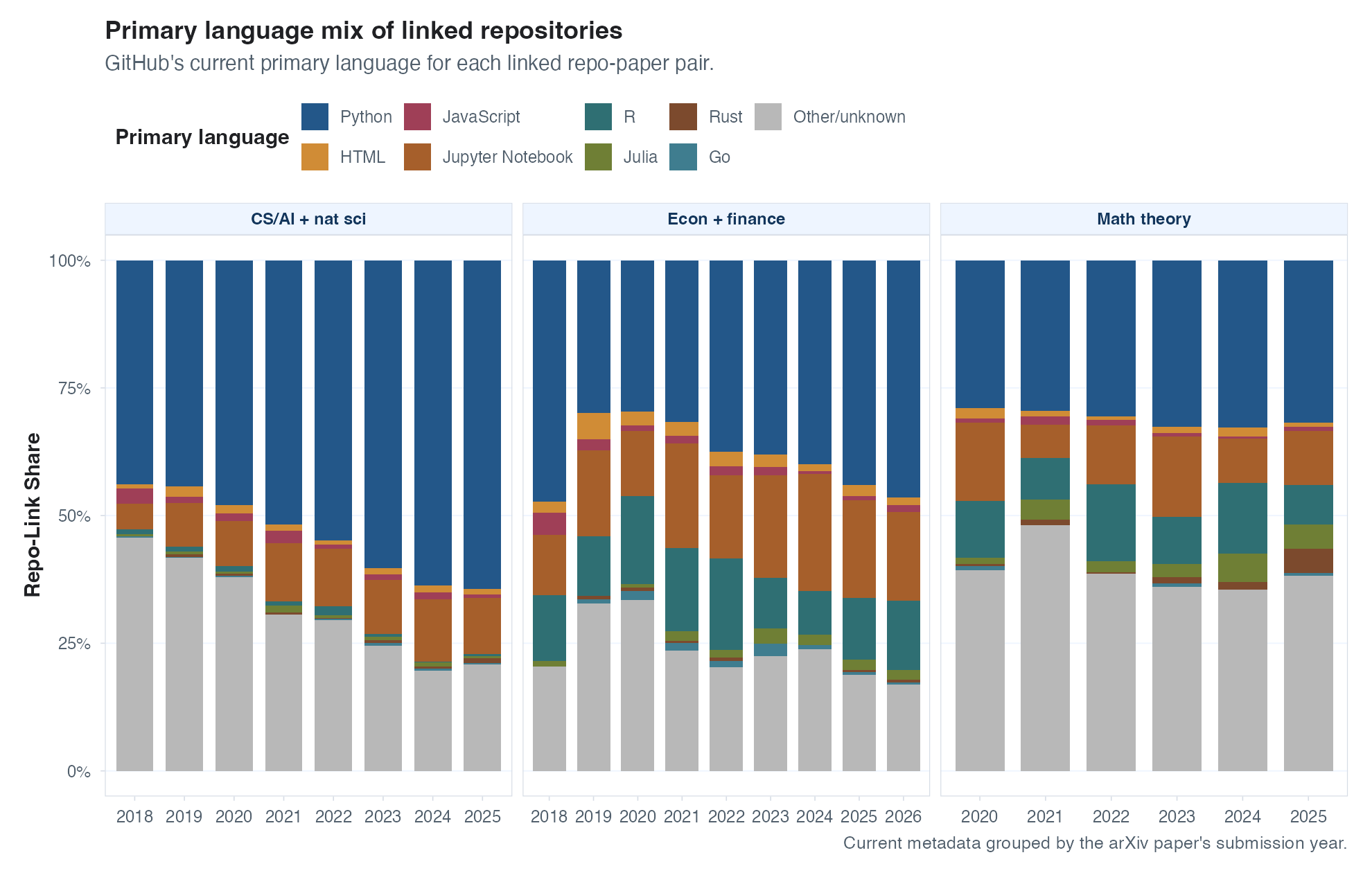
One other possibility is that the number of repos has stayed constant but each repo is growing in size. Maybe people are using agents to produce their replication packages, resulting in longer (and maybe better?) repos. So I had Codex download the metadata for all of the GitHub repos found in these papers (GitHub represents the vast majority of identified repos), and plot the distribution of repo size over time. Lines of code would be my preferred measure of size here, but the GitHub metadata doesn’t seem to provide that. We do, however, get to see total file sizes, which seems like a fine proxy. See the results below – I don’t see much action here in aggregate, but repos vary in size so much that any changes in the median are dwarfed by the variance, so I’ll tally this as there being not enough signal to tell what has happened in either direction.
Extra plots about GitHub metadata
More theorems?
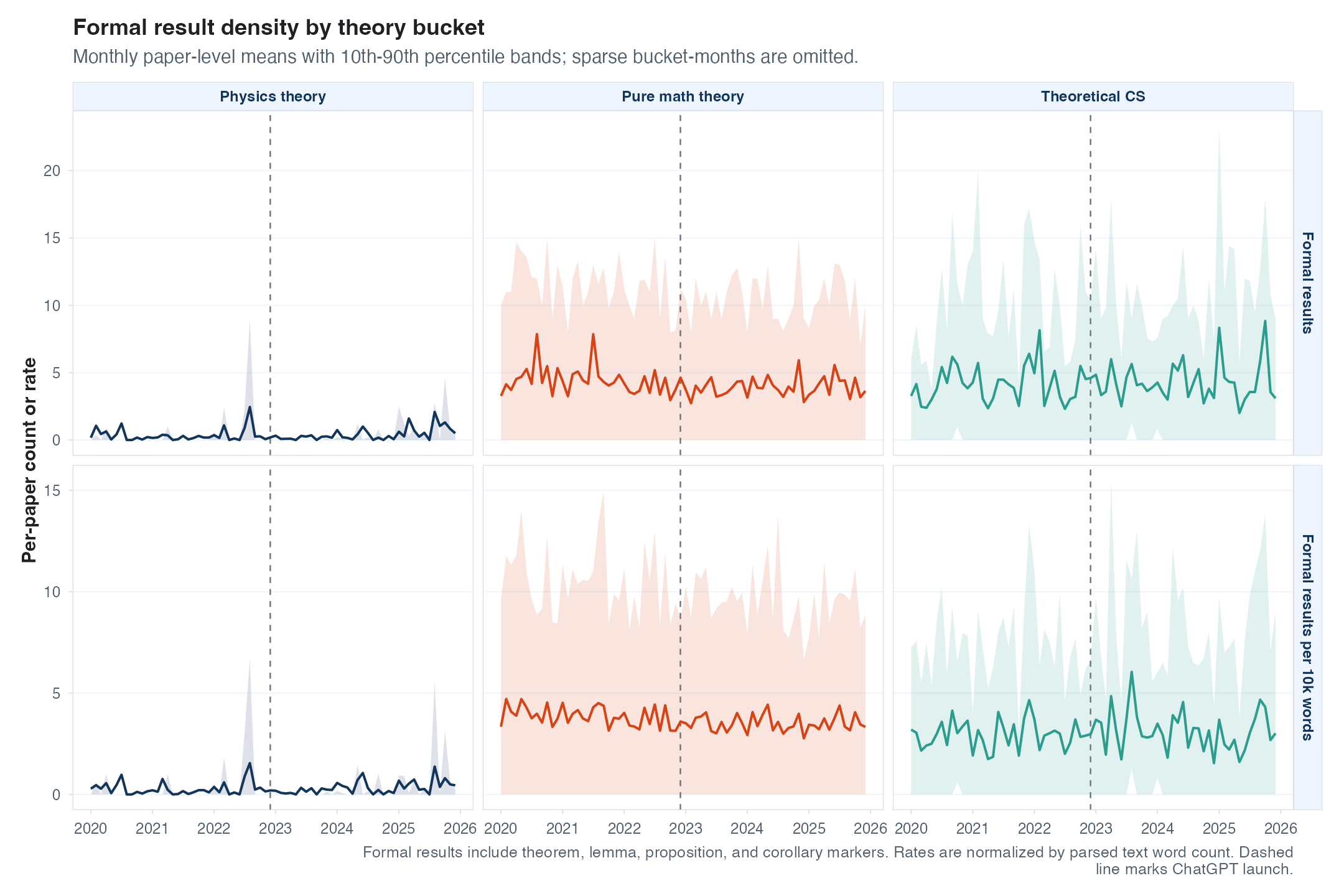
Tables, figures, and repos are all pretty weak signals. Multiple figures or tables might be used to present the same conceptual result. In math-y fields, there is a better option– let’s try to see if papers with some formal theory now have more formal results (theorems, lemmas, etc.) due to LLMs. If they did, I could see that being either a good or a bad thing for math. It could be that LLMs break big theorems into boring bite-sized pieces (resulting in more total statements), or that they help researchers append new results beyond their own skills. Of course, LLMs could also reduce the average number of theorems per paper through multiple mechanisms (e.g., entry from less serious mathematicians or easier ideas with a single formal result required).
Looking below, we don’t see much movement in either direction, unfortunately; there is again a lot of variance across papers, but the mean is pretty visibly flat, so no big jumps. This is true both in absolute counts of results and in the number of results per 10,000 words, which I thought might show something different if LLMs are writing more or less verbose text than humans normally do.
Paper and abstract text content
Next I wanted to do more digging into the actual text content of the papers. The arXiv metadata gives us abstracts and titles, and for the papers I downloaded I parsed the entire text body from the PDF.
Top words
First, we can do some really simple keyword accounting. Which words start showing up in abstracts and titles more often in response to LLMs, and which show up less often? Mostly, I see huge growth in mentions of LLMs (far beyond any other changes) and not much else. I do think it’s interesting to see what has shrunk in CS fields – computer vision papers are talking less about deep learning and convolutional neural nets? I assume everything is a transformer now?
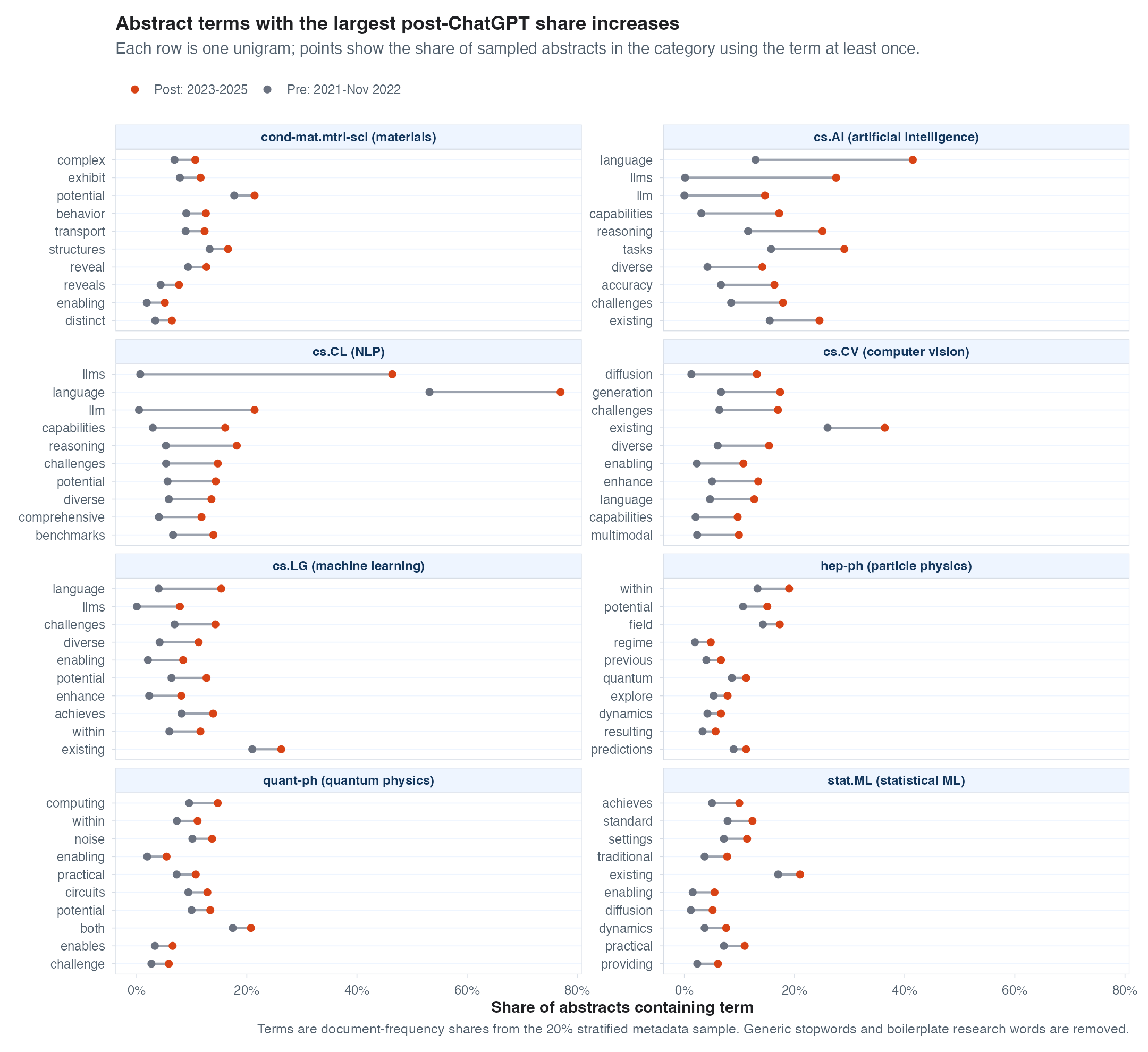
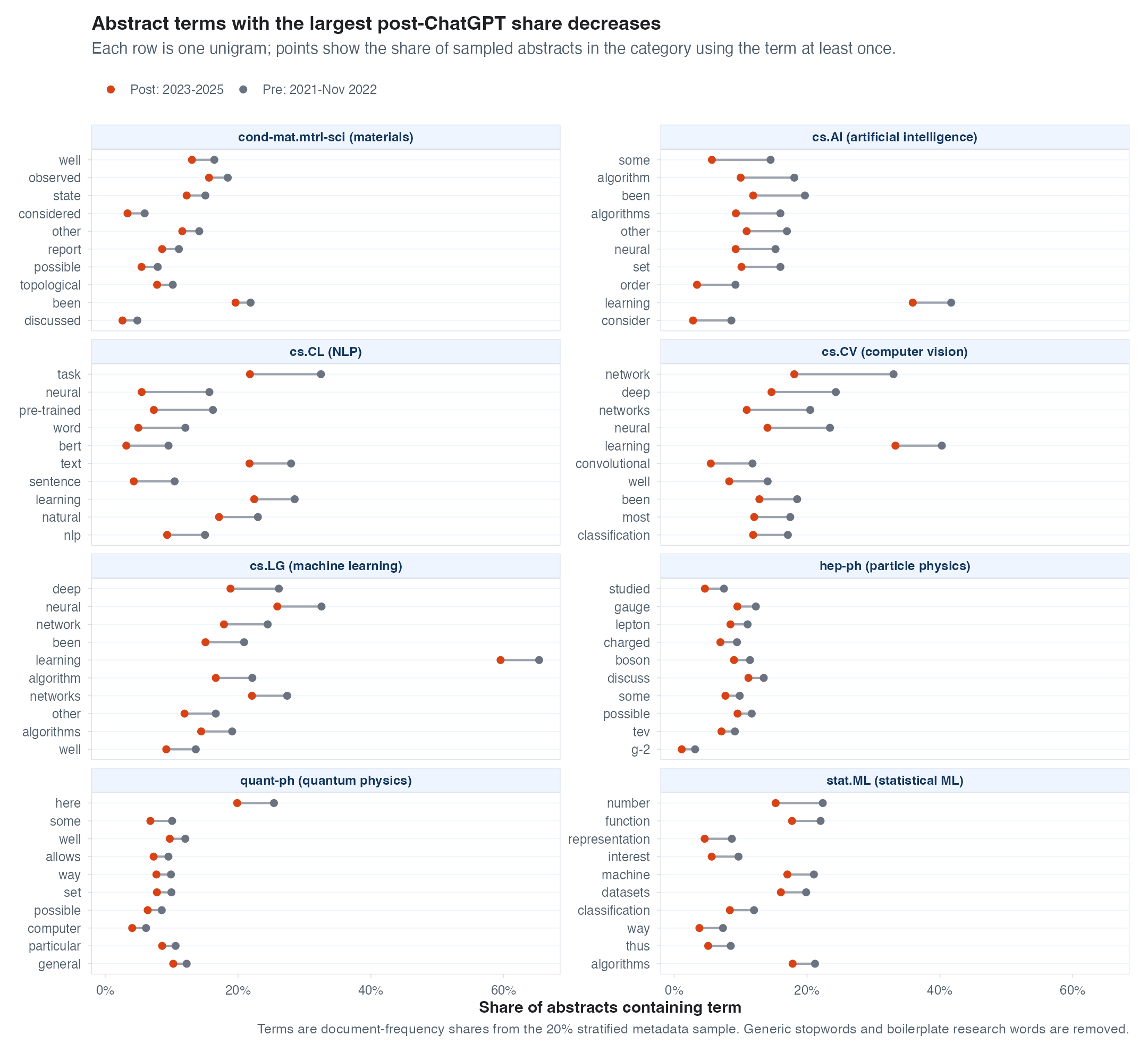
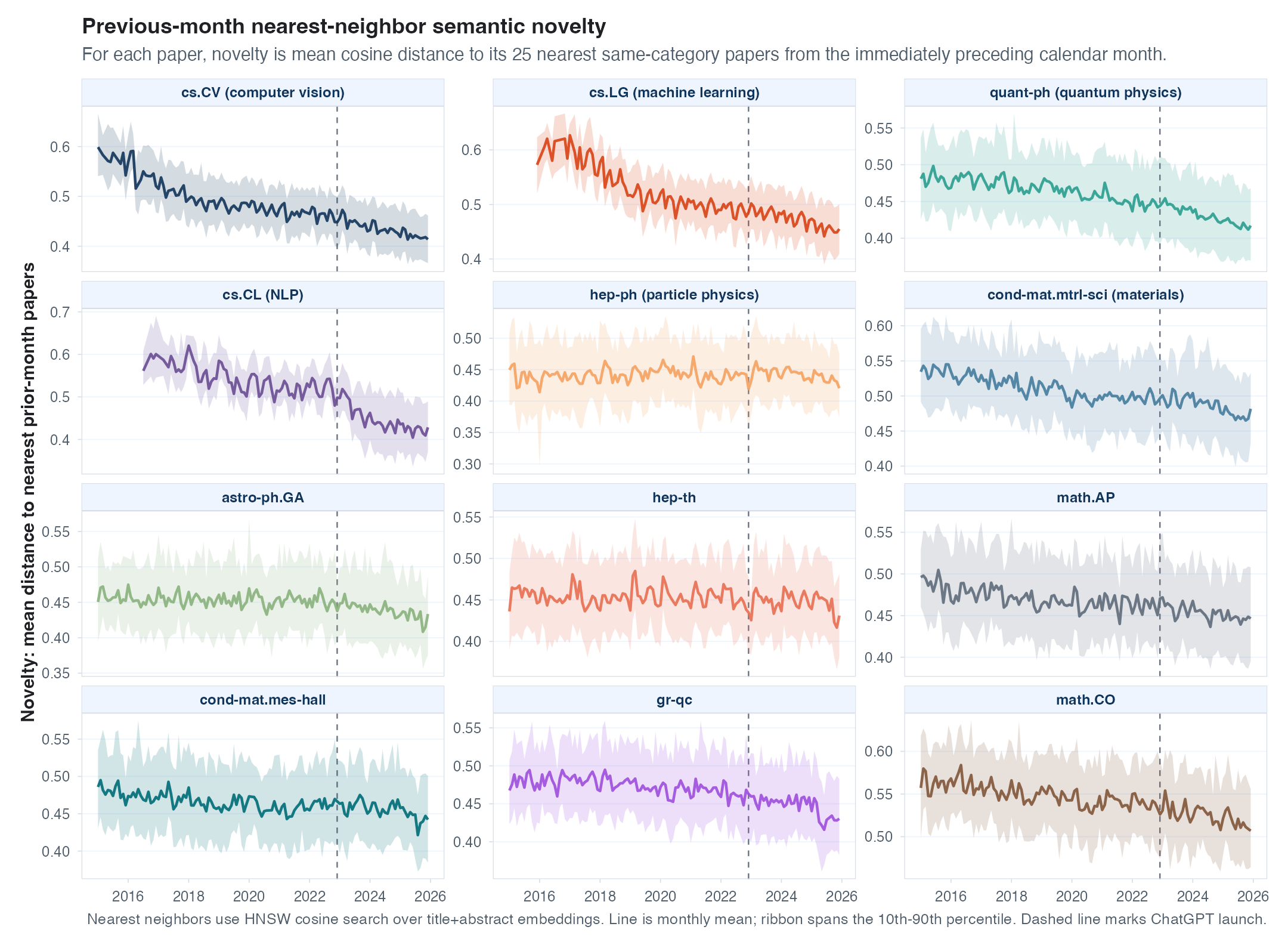
Abstract and Title Embeddings
Word counts don’t tell us much, so next I embedded a large sample
(380,000 papers) of titles and abstracts from 2015 to 2025 using
text-embedding-3-small from OpenAI. Then, below I compare
the embeddings of each paper’s abstract to the centroid of the 25
nearest abstracts (in the embedding space) from the previous month, and
plot the mean and 90-10 range of those distances over time. A couple of
interesting things in these plots. First, a general trend downwards
indicates that abstracts have become more similar, according to these
embeddings, over time. I assume those who conduct meta-analyses of
science would know more about why that’s the case than I do, but I found
that surprising. Second, the only major change I see here is that
cs.CL (NLP) papers quickly become more similar (smaller
distance to previous papers) as soon as ChatGPT launched. My assumption
here, especially given the previous section, is that this is due to the
field shifting toward studying and publishing about LLMs, not
necessarily the use of LLMs in conducting research.
Theorem quality
This final idea I wanted to explore in this post was a hail mary, but I’m really happy with how it turned out. It’s possible ex ante that the number of theorems/lemmas/etc. has stayed exactly the same but the rate at which proofs contain errors has declined through the use of AI as a reviewer. To test this, I had Codex extract theorem-proof pairs in bulk from the downloaded theory papers and then deploy GPT-5.4 subagents to review each pair and return complete reviews.3 Note that the fact that LLMs are imperfect proof reviewers is less problematic here than in some other “AI as a judge” work: because the goal here is to check whether LLMs are more likely to have been reviewing proofs before submission to arXiv, all we need to know is whether proofs are less likely to contain errors that frontier LLMs can catch. So this should, in principle, be a straightforward application of AI as a judge of proofs.
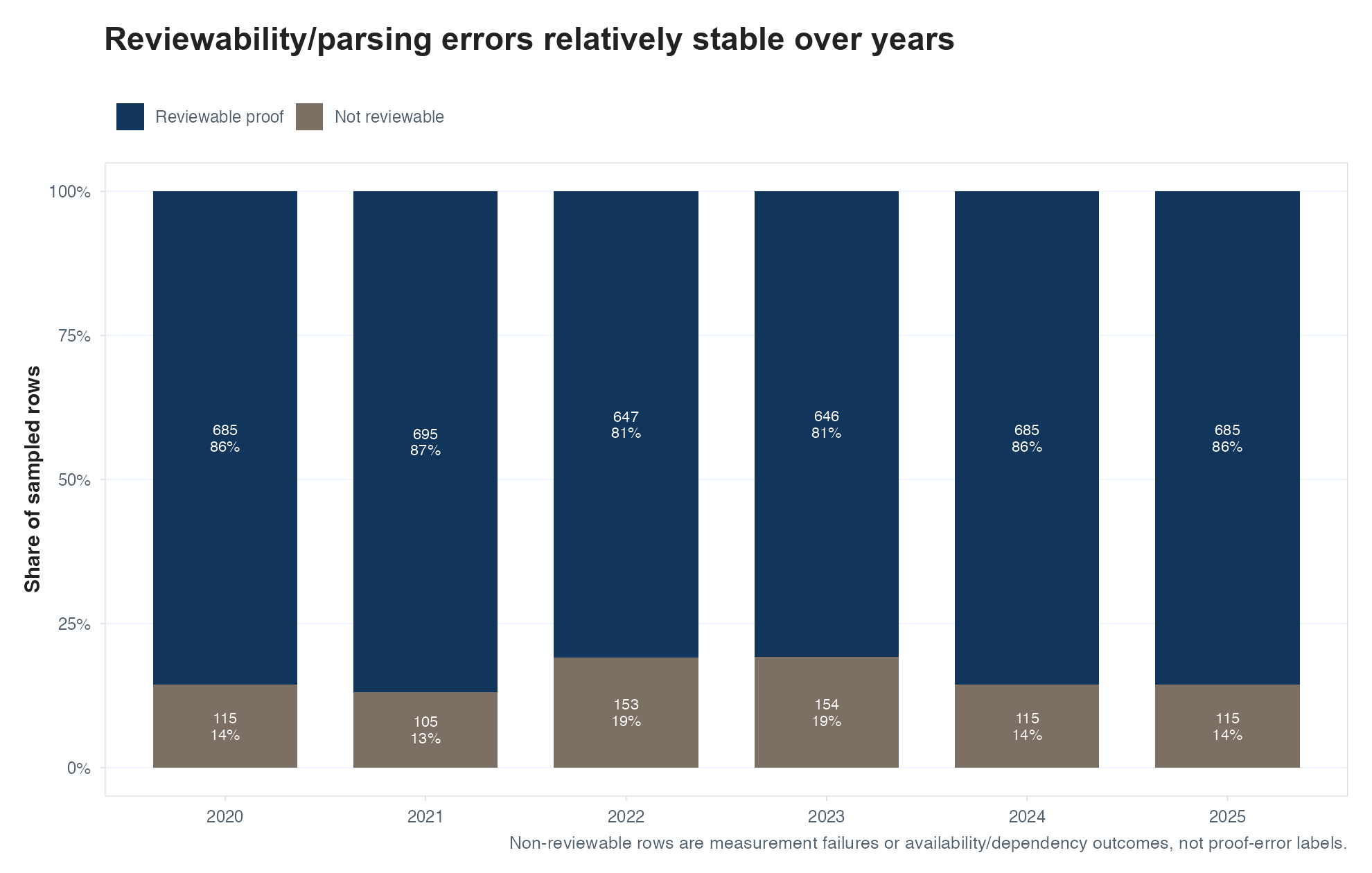
So after having GPT-5.4 (to save costs) agents review 4,800 proofs and GPT-5.5 give a second review to a random subset of them, what did we find? To my absolute surprise, if anything the rate of errors in proofs has increased(!) in 2025 relative to previous years. This is true for multiple definitions of what counts as a proof error (e.g., GPT preferred to flag key missing/unclear logical steps as errors), and notably some of the increase comes from errors that seem pretty easy to fix with LLMs – algebra, “scope mismatch” (GPT’s term for things like claiming sufficiency when only necessity is proven). I don’t suspect that LLMs are to blame for any increase, but I’m blown away to find so many little proof errors – not that I evaluated them myself, but if GPT-5.5 is mistaken this frequently that’s its own issue. If true, this might point to slow diffusion (I guess not everyone is checking every proof with AI?) being the biggest bottleneck here.
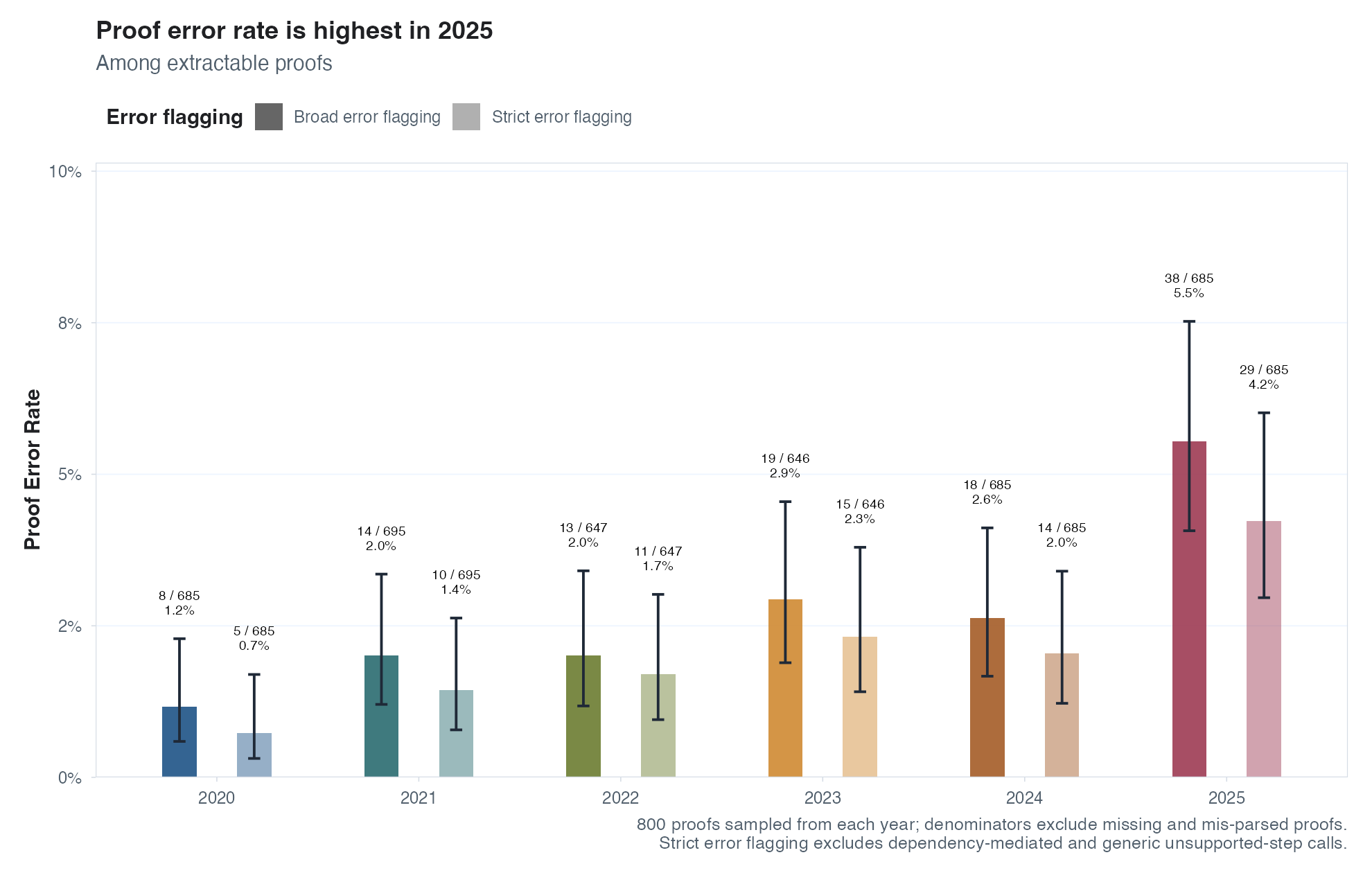
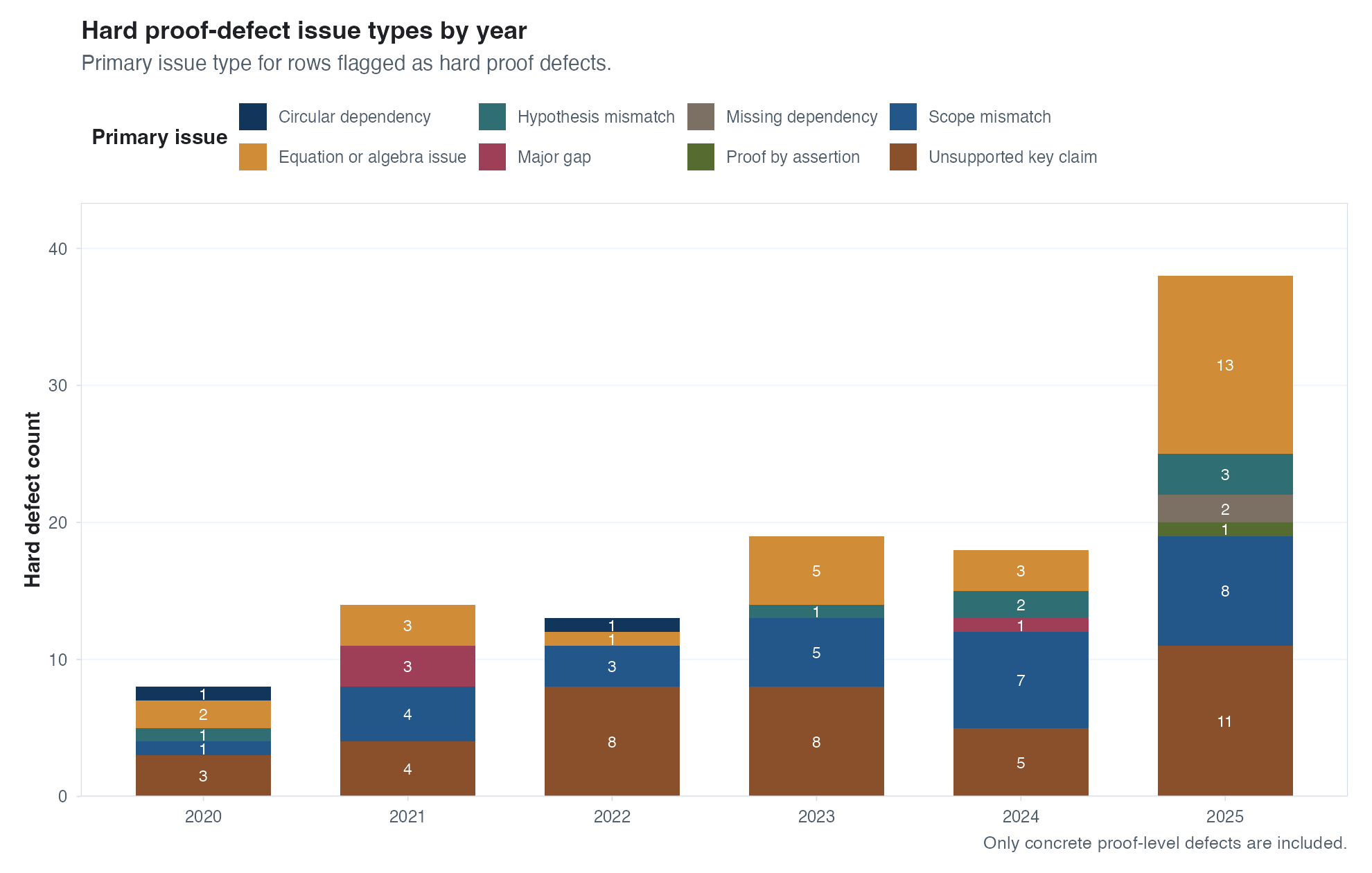
Extra plots (scroll)
Interpretations
This post was really fun to write, in part because AI absolutely did make my work so much easier and faster. No wrangling APIs, cleaning ugly datasets, etc. So, hopefully it’s obvious that I’m bullish on the opportunity for LLMs to improve science. However, I think emphasizing what is and isn’t happening today, or at least which measures of progress are and aren’t moving yet, helps us learn how to realize that potential.
I can imagine some mechanisms through which LLMs could be augmenting science that would be missed by what I looked at here. Maybe all measures of quantity of output could stay flat (or growing at the same rate) but the quality of every result is better. I tried to look at this, doing the same kind of AI-as-a-judge reviews of figures/tables/theorems for novelty and clarity, but didn’t find anything and don’t know that I trust AI judges for that (if you do, then I’ll save you the trouble and say that GPT-5.4 didn’t think theorems have gotten more novel or more important/substantive at all). I also find it improbable; there is a real quality-quantity trade-off to research production in my experience, and it would be odd to me if LLMs can only augment quality without allowing some researchers to deviate and produce huge quantities. There are other reasonable possibilities – maybe private labs have felt most of the gains, or maybe LLMs have unlocked longer-term research that has yet to be finished – but I’m skeptical of the ones I can think of.
If, however, what I see here is correct and science has not begun to accelerate at scale, here’s my brief mental model of the moment:
- Scientists are trained and practiced at coming up with a few good ideas per year, and LLMs have introduced an ideation/iteration speed in some fields that we are not ready for, making it difficult to incorporate them fully into research workflows.
- Lots of human bottlenecks remain. I need to understand the work LLMs do and my attention is finite; maybe all researcher attention is already used up and reallocation will take time. Hard sciences also have to test things in the physical world, which may be difficult to speed up.
- Frontier models are still too expensive. Just in playing around on my own, I can easily use all of the Codex $200/month plan’s tokens. Those seem quite heavily subsidized, and I assume I’m spending over $1,000/month at API token rates. If I were trying to develop new science, I’d need at least an order of magnitude more tokens (and maybe multiple orders). That makes the technology a substantial and risky cost, given that I might need to run many parallel agents to find the next big win (after all, if it were easy, surely I wouldn’t need to buy the tokens in the first place).
These points can all change over time, and if I were a big LLM lab I’d probably be spending effort on each of these: training and collaborating with scientists to figure out where LLMs can be injected during ideation and which tools are needed to build new explore-exploit loops; helping build better simulation tools to reduce dependence on physical hardware where possible and incentives for production/speed of physical experiment inputs otherwise; subsidies, or conditional subsidies, structured to incentivize the right kind of scientific use cases for my best models.
Footnotes
The three categories are composed as follows. Math/theory: primary categories in
math.*, plus theoretical CS (cs.CC,cs.CG,cs.DM,cs.DS,cs.FL,cs.GT,cs.IT,cs.LO,cs.PL,cs.SI), statistics theory (stat.TH,stat.ML,stat.ME,stat.CO), and theory-heavy physics (math-ph,hep-th,quant-ph,gr-qc,cond-mat.stat-mech,nlin.SI,nucl-th). Econ/finance: papers with anyecon.*orq-fin.*category:econ.EM,econ.GN,econ.TH, plusq-fin.CP,q-fin.EC,q-fin.GN,q-fin.MF,q-fin.PM,q-fin.PR,q-fin.RM,q-fin.ST,q-fin.TR. This includes cross-listed papers whose primary category is outside econ/finance. CS/natural science: primary-categorycs.AIpapers, plus natural-science archive categories fromastro-ph,cond-mat,gr-qc,hep-ex,hep-lat,hep-ph,hep-th,math-ph,nlin,nucl-ex,nucl-th,physics,quant-ph, andq-bio.↩︎To flag a “repo”, we consider any link to GitHub, GitLab, Bitbucket, Zenodo, OSF, Dataverse/OpenICPSR, Code Ocean, Hugging Face, or Papers with Code.↩︎
I also had them mark any cases where the proof was not successfully extracted, and anything receiving this flag was dropped. After a few iteration rounds, Codex got pretty good at building theorem-proof pairs, and the majority of flags come from theorems that either entirely omit proofs or omit enough detail that GPT wasn’t able to score them.↩︎