Do better, not more
Author: James Brand
Date: 2026-05-19
The world does not need another diatribe about AI progress, and yet here I am. What I’ve seen a lot of on the internet are product demos, brags about AI spending, and endless long-run forecasts/theories.
What’s missing, for me, is a framework for thinking about the concrete, nitty gritty, details of building with LLMs as of today (May 2026). How do I build trust in frontier LLMs’ output, at or above the level of trust I expect with a human collaborator? How often should I review the output? What tasks should I have it do, and which should I leave for myself?
I’ve never been a great theorist, so my best frame for thinking about this has been through my own experience, for whatever good that is: what are they good/bad/useless at in my projects, and what I think that means more broadly.
Starting assumption: most AI code (still) has to be fully reviewed
Because it’ll show up as an assumption below, let me start by admitting that I’m not yet convinced that we should be doing anything that matters with LLM code that hasn’t been reviewed by at least one human as if they were writing it from scratch. The figure below (from this Twitter post) is a nice re-frame of the popular METR LLM timing plots. Here we can see that, for tasks that are 1-4 hours, frontier LLMs have a hit rate of 75-80%.1
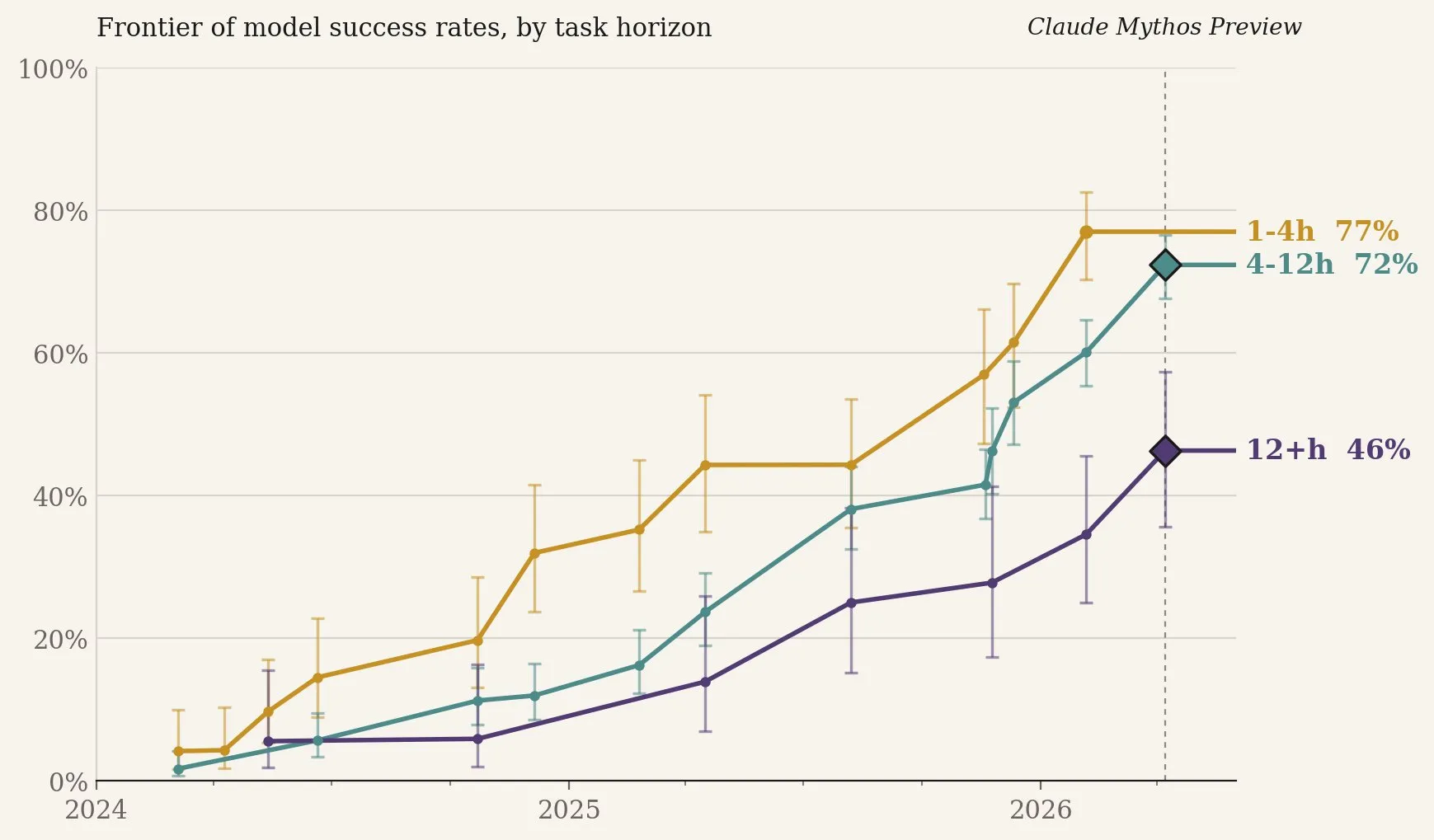
This rate is much higher for some tasks, but when I deploy an LLM to do something really challenging or big, it probably does 10 or 20 1-hour (human) tasks. After a few big turns, the odds that something is broken are actually quite high, especially as the code base bloats from the LLM’s own doing. Not to say that humans don’t also break code frequently, but as I’ll harp on below, the point is about how to dive into LLM-generated code and gain confidence in it. So, readers may disagree with this premise, but I’ll start from the idea that if you want to do anything important with AI, you probably still need a strong human hand involved at some point.2
How to scale myself
With that assumption, then the best way to use LLMs has to be through extending, or scaling, my own skills through some form or another of multitasking (as opposed to deploying an army to build the world). I have a simple picture below to show three versions of this I’ve tried. One is that LLMs help to scale down/deeper into something, to learn more deeply about a project than before and to execute and build something more complete than my time alone would allow. This type of self-scaling has worked well for me. For example, I like writing (niche) open-source packages for estimating economic/statistical models quickly. “Quickly” here was previously constrained by how many algorithms and coding tricks I knew. E.g., what’s the best way to implement this function if I need to be able to differentiate it thousands of times? Now, instead, I can lean on LLMs as a surveyor – “look at this algorithm in Julia/Python/R and tell me where I can reduce memory allocations” is all it takes to get an agent to try 10 language-customized tricks and report the best one. In this way, I can now go deeper into a project than ever before.

In contrast, anything that requires paying switching costs, across projects or (especially) across domains, has in my experience not gotten any easier to do well with LLMs. I’ve tried setting Codex off to write 5 packages at once, controlling and specifying each step while alternating between chats, and I’ve tried building full apps (frontend+backend) from scratch. No matter how many subagents, chats, or skills I use, I cannot get any serious amount of horizontal multitasking to work for me. It’s not that LLMs can’t do these things, but once they’ve done it, closing the loop so that I can then own the project myself has proved to be a bottleneck I can’t solve. If I have an LLM build the frontend and backend for an app, I then sit there with 10,000 lines of code wondering how I’m supposed to take the reins back from the machine.
The limiting factor here is, fundamentally, my attention. So I think a lot about how to spend that attention to produce more, high quality, output. Look at the two options below; both show a coder switching between projects. One iterates quickly with short tasks, and the other iterates slowly with big/long tasks.

The key difference between these is the amount of code that has to be reviewed in each turn (or, more realistically, the amount that goes unreviewed as the project grows). Sending the AI off to take bigger swings helps speed up the work, but results in bigger chunks to review. Which one of these to choose depends on the cognitive/attention costs the user pays as a function of the amount of code to review – examples below

I think I land closest to quadratic (or maybe even exponential) with fixed switching costs. So every flip between chats costs me a small brain fee, and the bigger the chunk of new code, the worse the cost. If I can be so bold, I imagine that many people face cognitive costs broadly of this form, where maybe the x-axis is something like “# of unique functions” or similar, instead of lines of code. If that’s the case, and if the quadratic component is steep enough, then short and quick reviews minimize costs:

This is where I’m starting to move in my work – after spending a lot of time in the Codex app firing off huge repo edits sight-unseen and relying on test design to prove the code is right, now I’m trying to move back into a GitHub Copilot and similar tools, looking at the code at all times and having Copilot implement tight edits while I watch. This comes at a cost though, and short-run incentives to build fast are difficult to resist (see this video by the creator of pi, for a catchy pitch that resistance is worthwhile).
Handoff problem
To be clear, I consider myself net bullish on LLMs as having a big impact on the software industry and thus the economy. If I’m starting a completely new project, need to dig in and edit a new big codebase (for prototyping), need a function fixed, or a consultant on algorithm design or complex programming language details, LLMs accelerate my work dramatically and that will matter in one way or another.
However, even when operating in my “depth” regime above, some important concrete tasks I’ve tried haven’t worked, and the more I think about it the less I see how the big labs can fix them. A few small examples that bother me, to make my point:
Broadly, LLM explanations of code are awful, long-winded, and make my eyes glaze over. Asking “what does this function do?” might give a 10-paragraph manifesto, even if asked to be brief/concise.
I’m a contributor to
dbreg, which runs linear regressions on remote databases using SQL tricks. When left alone to implement a completely new feature, I have had GPT say multiple times “I couldn’t figure out how to write this in SQL so I just pull the whole table into memory and do it in R” – a mistake so awful and breaking in this context that even extremely junior devs would know betterI’m trying to use LLMs to write package docs, and they are terrible. Even Codex’s
/goal, in which you can push Codex to continue iterating almost endlessly, does little to move the needle. One set of docs, for example, has 5-10 pages in Quarto/html. The ask is simple: document an R package’s features and run some benchmarks. After hours of the LLM working, I open up the docs and see, on top of the AI-dripping prose like “it’s not a package for X, it’s Y”, figures with broken legends and empty data and website text that refers to my 1:1 chat with the LLM (i.e., which no user could understand). Maybe the funniest thing it does is add very pretty nonsense like the screenshot below to my docs homepage, explaining choices it made to me the chatter, whereas it should be explaining things to me the package user.

LLMs can’t teach me what they’ve done
In short, all three of these examples point to one big shortcoming: that LLMs today still lack some sort of conceptual framework of the work they do – described well by this tweet as LLMs still lacking theory of mind. If I asked a smart human to write code for a week and report back, they would be able to walk me through the code line by line, describing their vision for the structure of the project, for each file, and for each function. LLMs get lost in verbose explanations or details that are irrelevant for the explanatory step at hand, which then also trips them up and makes them make insane mistakes.
Maybe my best piece of external evidence that this is a problem is that the Dwarkesh podcast recently started a blackboarding series in which a technical expert comes in and teaches him (and the audience) how LLM inference works or how to build Alpha Go. There’s a deep reason that, even though frontier LLMs know both of these topics in extreme detail, humans are selected as teachers on the podcast.3 Something is missing between the ability to do and the ability to explain, and until that is fixed I worry that building too much, too fast, with AI is a risky bet.
Summarizing
In summary: as many have noted, prototyping is more accessible than ever before. But completing the loop, to get my brain to understand what has been built and take up the mantle, is still (shockingly) weak. It’s also very hard for me to imagine a good validation loop for RL-ing this into LLMs (but I don’t have a great imagination). The best technical human teachers are extremely adaptive, perceiving the student’s understanding in real time as it evolves and testing different approaches to meet the student where they are. I think, until recently, I didn’t realize how important the specific skill of teaching is to limiting the real value I get out of LLMs in my work trying to make things.
I’m sure some big lab will prove all of this to be outdated in the near future as compute continues to scale. I often hear AI zealots say that anything verifiable will eventually be conquered by LLMs, and I think I’m a believer in some slightly weaker version of that claim that allows some tasks to just not be worth the squeeze of data collection and training. But with enough compute, we’ll get the 1-hour success rates for many coding tasks up to 99.9% and then I’ll feel much better just trusting raw LLM output (if compute costs decline by a couple of orders of magnitude, that would also fix a lot of my concerns). Even better, there are lots of great use-cases that can make do with much lower success rates; security issues, for example, only need to be found once. If I were working on a product, I’d be first in line to ask LLMs to hunt for security issues like Cloudflare.
So as of May 2026, my view is that LLMs already dominate for anything that either converges into a single, bite-sized, reviewable output – hence the many claims from AI researchers that their work has been accelerated, and hill-climbing projects like nanoGPT. But where human verification is costly (like many business settings, in my experience), I still worry a lot about the proliferation of quick builds and pressure to move fast.
Aside – I would kill to see a version of this plot where the time measurement is time for a human to verify and understand the code.↩︎
The key here then is what is “important”, and what does human “review” mean? I’m flexible here.↩︎
Part of that is sociological – maybe “listening” to a robot voice would be worse entertainment – but I don’t think that’s all of it.↩︎