Distributed/compressed regression rocks
Author: James Brand
Date: 2025-08-24
TL;DR: This is a quick post about a relatively new pair of packages meant for fast, SQL-backed, regressions with fixed effects in R and Python.
I’ve only recently discovered the Python package duckreg (by
Apoorva Lal and coauthors) and the R port dbreg by Grant
McDermott, but I wanted to make a quick post about how amazingly fast
these packages are after being blown away while testing them. Before I
was as familiar with R, from the outside I thought that
fixest was unbeatably fast for linear regression with fixed
effects. Generally, fixest is definitely still king for
most applied work. However, the benchmarks I’ll show below suggest that
it can be beaten in at least one case (extremely large data), which has
gotten me excited about big regressions using SQL backends. I wanted to
share the excitement with this brief post. Full disclosure, I made a
modest PR to dbreg recently so this is probably partly self
promotion.
The idea(s) behind
duckreg/dbreg
These packages are supported by a couple of key papers:
- Wong et al. (2021)
- Demonstrates the optimal (lossless) “compression” that can be applied to large datasets to allow estimation of linear regressions and standard errors
- Wooldridge
(2021)
- Introduces the two-way Mundlak estimator, (among other things)
allowing the inclusion of unit- and time- effects without “absorbing”
the fixed effects in the ways common packages (e.g.,
fixestin R,reghdfein Stata,FixedEffectModelsin Julia) usually do.
- Introduces the two-way Mundlak estimator, (among other things)
allowing the inclusion of unit- and time- effects without “absorbing”
the fixed effects in the ways common packages (e.g.,
In short, these two papers together show that (a) regressions can be broken down into a “compression” step, which uses any desired backend to shrink large datasets into much smaller matrices, and then an incredibly fast estimation step using that output, and (b) that two-way fixed effect regressions can be estimated simply by including a couple of carefully constructed additional regressors. Combining these two means that we can run (up to) two-way fixed effect regressions by constructing the appropriate additional covariates and then compressing accordingly. Whether or not this is faster than existing methods when the data can fit in memory, the key value of this strategy is that it unlocks the ability to run regressions on datasets that are far too large to hold in memory. In testing these packages, I was able to run event study regressions with billions of observations and many millions of fixed effects, which had previously been infeasible, in just a couple of minutes.
Maybe the coolest thing about these ideas is that they’re basically
completely agnostic about the backend being used, becuase they rely on
simple group aggregations that can be done via SQL. So, barring the
implementation kinks of a young package, the tools dbreg
offers should be indifferent to whether you’re connecting to a DuckDB
database, a SQL Server endpoint, or just running a regression on a big
dataframe in memory. Switching between these seemlessly without jumping
between packages is, as someone who already alternates between
languages/tools too often for my taste, a very nice side benefit of the
use of generic SQL in both packages.
Benchmarking
The first pass at the dbreg package only implemented the
original Wong et. al (2021) approach to compression, which works very
well when covariates are discrete and when there are many observations
per unique combination of fixed effects and covariates, but does not
work well with continuous variables. The most recent version, however,
implements some of the “Mundlak” functionality in duckreg,
which has led to some amazing speed gains. As a benchmark, look at the
way fixest::feols and dbreg now scale with
sample size, in a setting with two covariates and two dimensions of
fixed effects (unit and time).
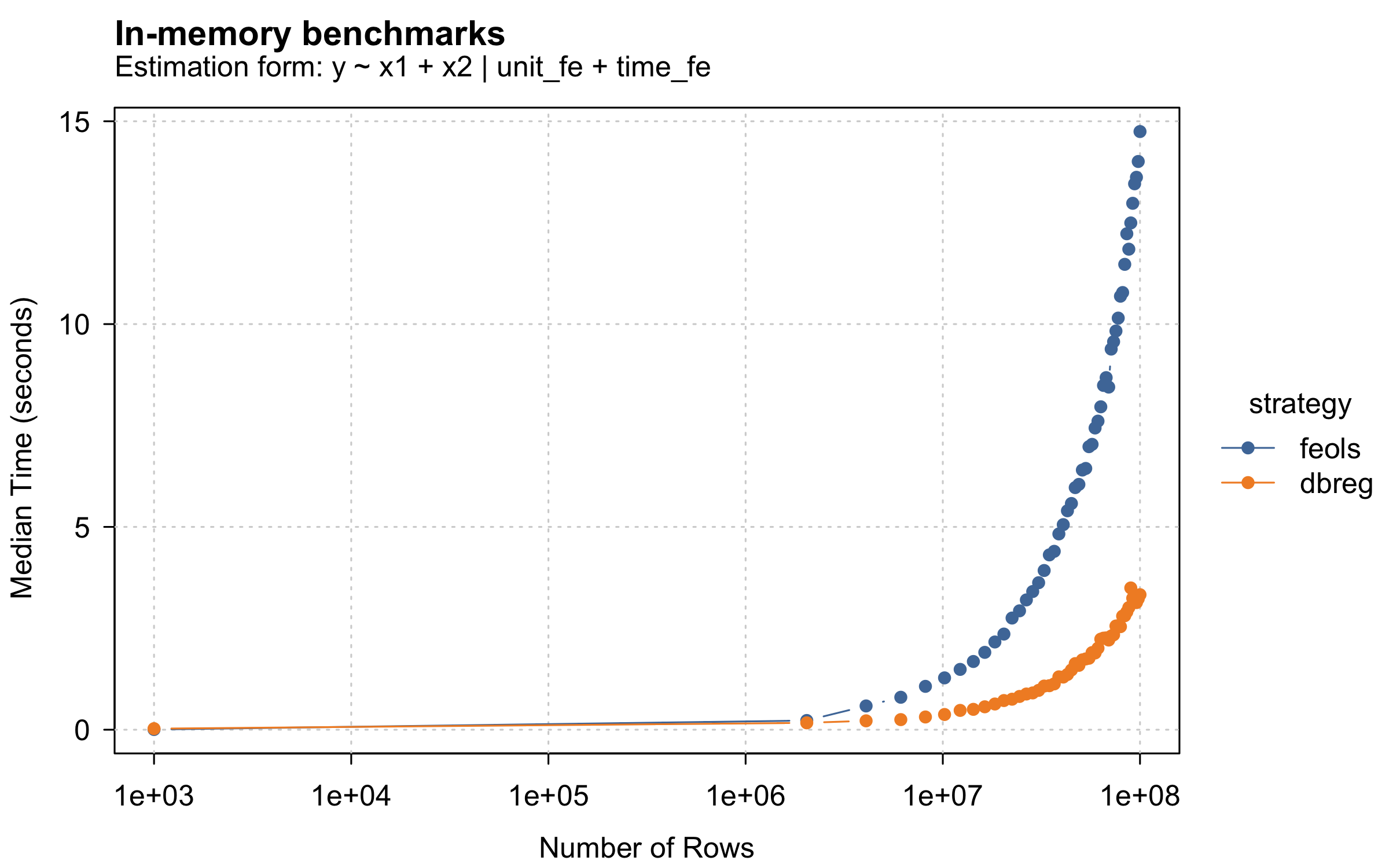
Clearly, dbreg beats feols handily here for
large datasets. For comparison, check out the
fixest/pyfixest benchmarks below (plot taken
from the latter’s repo). I didn’t spend any time trying to line up the
two benchmarks (i.e., the number and structure of fixed effects), but
you can see that in the two-FE case below (middle), feols
takes a little over a second here (~2.2 seconds) for the largest dataset
and is (barely) the fastest among all options. pyfixest is
also super fast, especially for larger regressions. However, for
regressions of comparable size (1e7 rows), dbreg takes less
than 0.4 seconds. Moreover, dbreg can handle 1e8 rows in
only 3.3 seconds. Again, not apples to apples, but handling ~10x the
data with only a ~60% time cost is awesome regardless.

Note that the speed here might seem like splitting hairs, but every little optimization matters at scale and in production settings. At tech companies with huge telemetry databases that far exceed the timings here, or in settings where inference is conducted via boostrapping the same regression repeatedly (both of which are common), we’re talking about a huge amount of time saved in practice.
Planned work
My experience has been that truely “big” data is stored in some sort
of database backend, and I’ve seen people sacrifice statistical power by
either sampling from these large datasets or using other statistical
methods that don’t make as good a use of the available data as
regression does. So, in a sense, duckreg and
dbreg were an overdue addition to the data scientist’s
toolkit that allow us to get lossless regressions on the “big data”
everyone has been talking about for decades. This alone has felt like
unlocking a superpower, and now the question is just how much of a DS’s
compute for other, or more complex, tasks can be offloaded to a SQL
endpoint, which is still unclear to me.
That said, I don’t expect dbreg to compete with
fixest for general use cases. However, I’m hoping to
continue contributing to dbreg, and I think there’s a good
bit more that can be done relatively quickly. Some low hanging fruit,
just to get it up to par with duckreg, are GLM support and
easy event study regressions, which likely cover a big share of common
use cases for regression on giant databases. Longer term, I’m fairly
bullish on more complex tasks like higher-order fixed effects or binned
scatters, and on speed optimizations for wider regressions than those
benchmarked here.