Let’s teach an LLM to play a game
Author: James Brand
Date: 2026-02-16
Note: Everything below was heavily AI assisted; I’m not an ML guy by training, so very possible I’ve made some silly choices or missed important papers! Excited to hear where I’ve done so. Similarly, I am not an AI researcher in any real way, so this is just a fun side experiment that has nothing to do with my job.
TL;DR: I taught (via reinforcement learning) Phi-1.5 to play the Tower of Hanoi to see if teaching it easy problems would unlock the ability to play harder problems. Mixed results, but mostly negative in my view.
Overview
The starting point for this post is that I’ve been perplexed by the lack of creativity in public benchmarks specifically concerning whether LLMs can truely extrapolate from their training data to new, or harder, problems. Admittedly, LLMs offer a unique challenge here relative to old-school ML, both because they are (pre-)trained on a huge corpus of quasi-unknown stuff and also because the tasks they are often doing don’t fit trivially into an “in-sample” vs. “out-of-sample” split. Is generating an image of a newly imagined object, writing a poem like a pirate, or even solving a new proof truely out of sample? In each case, there’s an argument to be made that the model is approximating or fusing examples in pre-training data that only appears novel to the user (a point that has been made too many times to cite a particular person). Maybe LLMs just combine existing text really well.
In some ways, that distinction doesn’t matter at all! If I can get an LLM to do a task I needed done and wouldn’t have otherwise been able to do, then I’ve gotten a ton of value out of it. Even explicit interpolation/prediction can be very useful – I’ve written about some of the ones that interest me, like market research and augmenting other prediction problems.
However, I do think that fast AGI take-off (“foom”) stories are a little harder to tell if we think most of what is happening is in-sample/interpolation. If we could make LLMs do tasks that are harder than anything they were trained to do, there’s a real “foom” argument: we’re going to spend $XX billion on RL to make something that knows how to prove every existing math theorem, and then it’ll start to crank out brand new research until we know everything we solve every problem ever. An interpolation-only story instead would mean something more like: companies spend a lot of money to teach agents about important subjects or tasks, and then LLMs serve as tools for connecting the dots between unrelated fields and/or extending existing results via known methods. This would be extremely valuable to the world, but a more manageable form of technological change and dispersion than the story of self-improving AGI that will be better than us at everything. Instead, the best AI would be better than any individual human at every task that we teach it, but many tasks would not be taught and many hard problems will still require tons of human effort to solve in collaboration with AI.
So, with uncertainty about which world we’re in and a limited budget, I wanted to try some (heavily AI-assisted) experiments of my own to see what extrapolation looks like in simple cases, hoping I’d learn something useful more broadly. As a secondary goal, my hope is to get a vague sense (ackowledging how inefficient my RL probably is) for how costly it is to teach LLMs all of these tasks.
Briefly: what do we know about LLMs and extrapolation?
Note: This is not my home literature, so my search for papers was as heavily LLM assisted as the coding itself! I have observed as an interested outside party for a while though, so hopefully I caught a few of the big papers.
Prior to LLMs, we had models like AlphaZero and AlphaGo, which made huge waves by beating the best humans at various games. Although these precede today’s LLMs, the way those models were trained feels informative. The AlphaZero paper in Science, for example, says “We trained separate instances of AlphaZero for chess, shogi, and Go. Training proceeded for 700,000 steps […] starting from randomly initialized parameters.” Another AlphaZero paper studying chess variants does something similar, saying “We trained AlphaZero from scratch for each of the rule alterations in Table 1, with the same set of model hyperparameters…”.
Although not the authors’ point, should this raise our eyebrows a little about cross-learning in pre-LLM RL? Why not train the all-chess-variant god-like model that can play everything, if that were possible? Importantly, these models are way cheaper to train than cutting-edge LLMs, so scaling one up to test generalization would be a drop in the bucket for a major lab.
There are also some serious efforts to study whether LLMs specifically perform well on held-out data/tasks (among many, Sanh et al, 2021 and Ilharco et al. 2023). However, skimming a lot of papers on this, most examples I see of “held out” data seem to be similar enough to pre-training data that results could be driven by some kind of interpolation. Even extremely recently, new work shows that some big training datasets contain examples that are pretty similar to benchmark puzzles. So, in essence, I think we should start a little incredulous of claims of extrapolation into new tasks from LLMs.
Reasoning models are a whole other beast, and it’s much harder to find good papers on interpolation/extrapolation with them, so I’ll skip the few papers I found.
Measuring out-of-distribution learning with games
So, with all of this existing work out there, I still feel like the question of whether, when, and how LLMs extrapolate (from the skills they are explicitly trained to do) is really not clear. Doubly so for RL-learned skills specifically, given RL’s centrality in what the big labs say they’re working on. The core problem, again, is that the “distribution” we want to measure performance “out of” is so high-dimensional and confirming what was in-sample during training is impossible.
Given that impossibility, my proposal for defining and studying “out of distribution” (OOD) extrapolation after RL is to go back to RL’s roots in games. Games are an easy setting both to define and scale complexity and to verify successes. For some reason, it seems like studying games with LLMs has grown out of favor, replaced by more complex (and more opaque) tasks and benchmarks. Specifically, here’s what I propose we do:
- Identify a game variant the LLM is unable to solve reliably above
some complexity threshold.
- This is our way of making a practical construction of out-of-distribution that we can actually play with.
- Use RL to teach the LLM a subset of tasks
- Evaluate on alternative rulesets and levels of complexity outside of the RL training sample
This simple process doesn’t pin down tasks that are OOD from pre-training data – I assume many common games show up somewhere online – but it does give me a baseline to think about OOD evaluation coherently for post-training. No matter the original pre-training, if the LLM is bad at task A and gets better at it after I teach it task B only, I’m willing to call that extrapolation in a way that I think is important and can be scaled.
The specific setting I chose here is the Tower of Hanoi. I chose this for a few reasons:
- Easy to describe the state space and actions in very very few tokens
- sub-point: most LLMs have seen it, so I don’t need to explain the fundamentals of the game
- Easy to control complexity and create variants
- Number of pegs
- Number of disks
- Target peg for completing the game
- Existing discussions (spurred by Apple’s paper) showing that LLMs can fail hard variants.
Setup/design
I ran a bunch of tests, but there are two main training runs in which I try to teach a small language model to play the Tower of Hanoi:
Randomly generated initial states for games with 3-4 pegs and 3-4 disks.
More flexible run, varying the number of disks from 3 to 6 with 3 pegs, as well as 3-4 disks with 4 pegs.
- I also ran a second version of this run (from scratch) with only 2M steps, to see how much variation across runs there was
In both cases, the training run fixes the target peg (the peg on
which the disks need to stack) at peg 2. I run each for 5 million steps,
which is a pretty long time for this game (the solutions to 3- and 4-peg
games are in the low tens). I use phi-1.5 from Microsoft in
the interest of computational efficiency, and update model weights via
LoRA using PPO+GAE (trying to use ML terms here, though econs would
usually describe them differently). The reward is +100 for winning, -1
for every legal move, and -10 for any illegal moves. Training and eval
are both done with temperature at zero (a comment on this
choice in the last section).
During training, games are initialized randomly within the desired game variant, and I allow at most 300 steps in each game before calling it a failure (this is very non-binding for small games, but more aggressive for larger games, I’ve learned). I run a small set of evaluations every few thousand steps as well as a much larger set at the very beginning and end of runs. For small problems (< 5 disks, mostly) I run through every possible initial state. For larger problems (5 disks or more) I select a sample of 10-ish problems that have optimal solutions at least as hard (by number of optimal steps) as the median initial state.
Results
We’re really looking for one simple thing. Can I teach the LLM one problem and have it start to solve other problems that are outside of the training distribution? TL;DR: Not reliably/cheaply!
First, let’s look at some cool learning plots. Below, I show the
results from my initial run (3d+4d), plotting phi-1.5’s
performance on each eval (measured by the share of initial states that
it can correctly solve) over training steps. We see here that the LLM
learns how to solve 2-disk and 3-disk problems quite quickly. Note that
we are not teaching the LLM to solve 2-disk problems
directly, so in a sense this is our first extrapolation test and it
passes! 2-disk problems are solved first, then 3-disk, and both within
200k-300k steps or so. So far, so good.
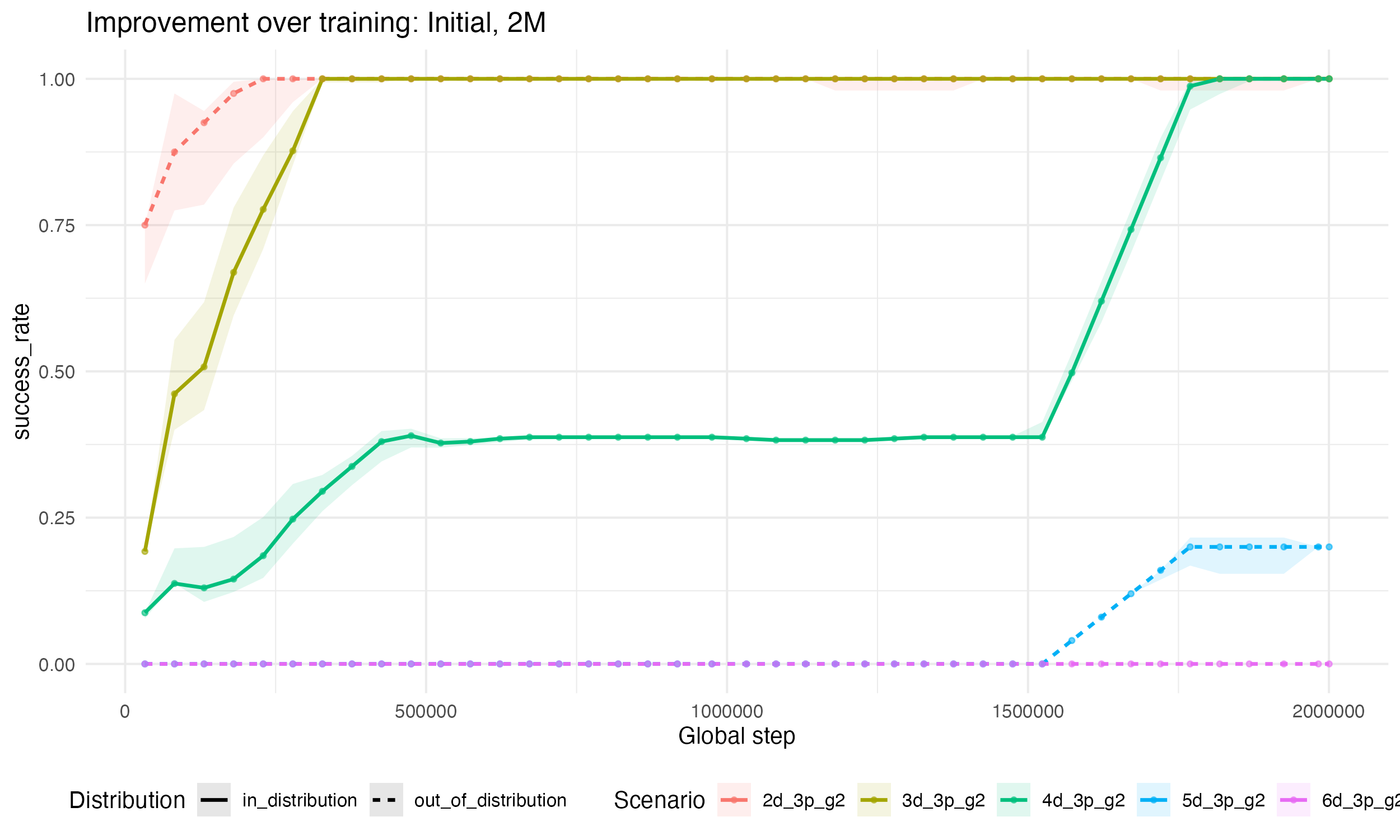
It’s also really cool to see “quanta”-like behavior (see this blog post for one of my favorite gifs of all time); the 4-disk problem here sees almost no gains for nearly one million steps! Then, all the sudden, the problem seems to click and we make relatively fast progress toward completion. The last thing I’ll point out here is that we have some little hints of extrapolation at the end of training – the LLM starts solving our eval 5-disk problems (which I selected to be non-trivial, see above) at a non-negligible rate.
That motivates my second, much larger run: if we started to see glimpses of extrapolation at 2M steps, maybe at 5M we’ll see big leaps into new domanins. So, let’s look at the results when we add in more complex settings into the training run (5-disk and 6-disk), and run for 3M more steps, below.
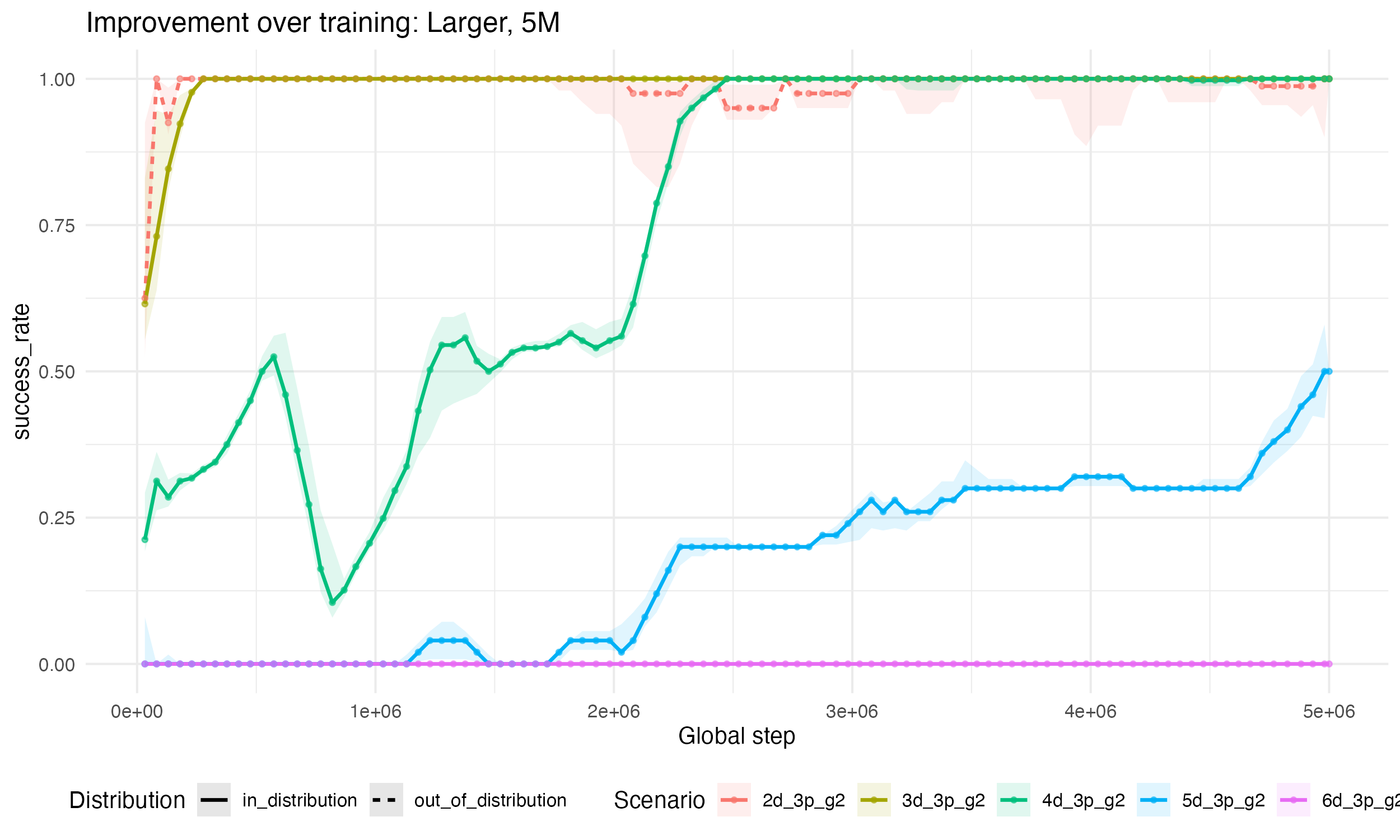
I see two takeaways from this bigger run: first, note that we actually learn the 2- and 3-disk problems significantly faster here. That could either be because the signal from harder problems help guide the optimizer, or just random chance from different initial points (e.g., see that we actually learn 4-disk problems slower in this run). Second, although 5-disk is now in-distribution, we really don’t make as much progress on it as I expected. On the hard-ish problems we’re running regular evals on, we are only hitting 50% success rates even after 5M steps. Of course, it does look like we hit a nice inflection point more than 90%(!) of the way through training and could have gotten further improvements
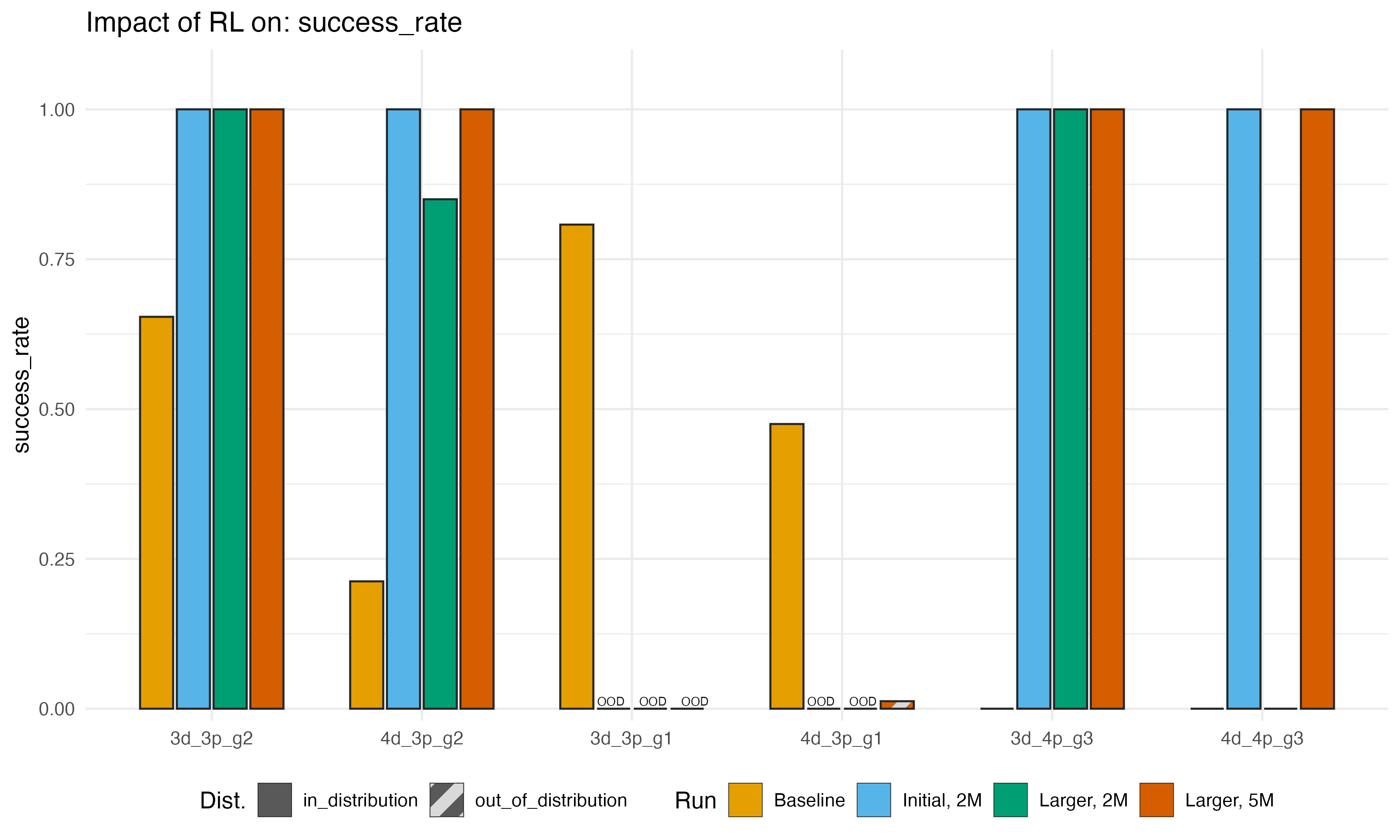
Now, we can zoom out and compare the baseline (no Hanoi RL) and final
post-training performance on a variety of game variants from three runs:
the initial smaller training distribution, the larger distribution, and
then the larger distribution run for 5M steps instead of 2M. Here are
some performance metrics below. In the top graph, we show the success
rate (trimmed to allow at most 300 steps) across eval scenarios (for
reading: 3d_3p_g2 denotes a problem with 3 disks, 3 pegs,
and peg 2 being the desired target peg).
We see consistently great results for problems that are in-sample and relatively easy (3-4 disk problems), especially if we don’t change the target peg. When we do change the target, we get surprisingly mixed results – if we try to move to peg 1, not only did training not improve performance, it actually made the model much worse! On the other hand, moving from peg 2 to peg 3 seems more-or-less fine. The baseline was, for some reason, awful at this, and some of our runs actually make huge improvements. I have zero explanation for this! But it is interesting.
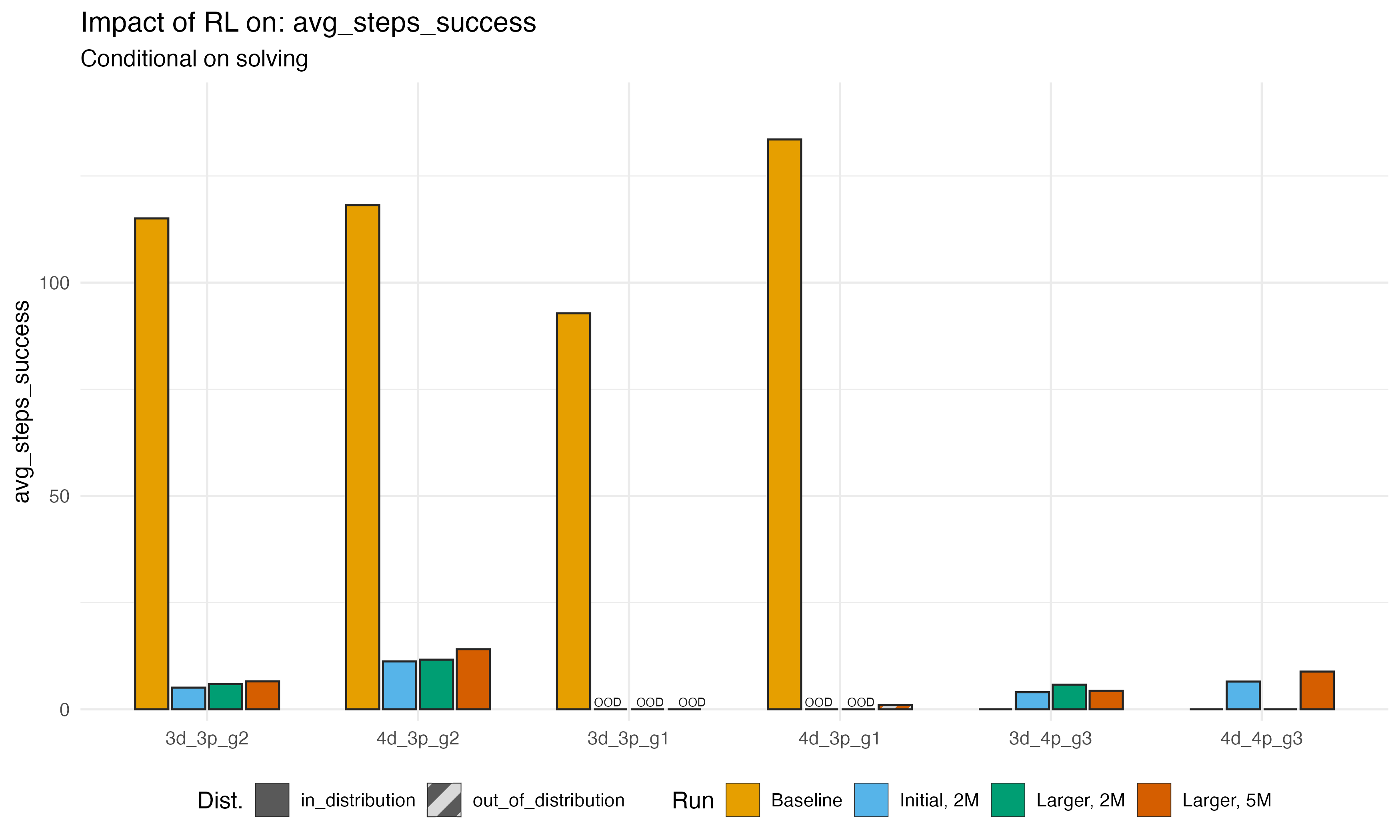
We can also look at the average number of steps taken to complete
tasks conditional on completion in less than my upper
bound of 300 steps. This is mostly consistent with the success patterns
above: if the LLM became more likely to solve the puzzle, it also tended
to complete it faster. The only surprising thing here is that pattern is
true even in 4d_3p_g1; the LLM barely learns to solve this
problem at all, but when it does, it solves it very quickly. Again, no
explanation.
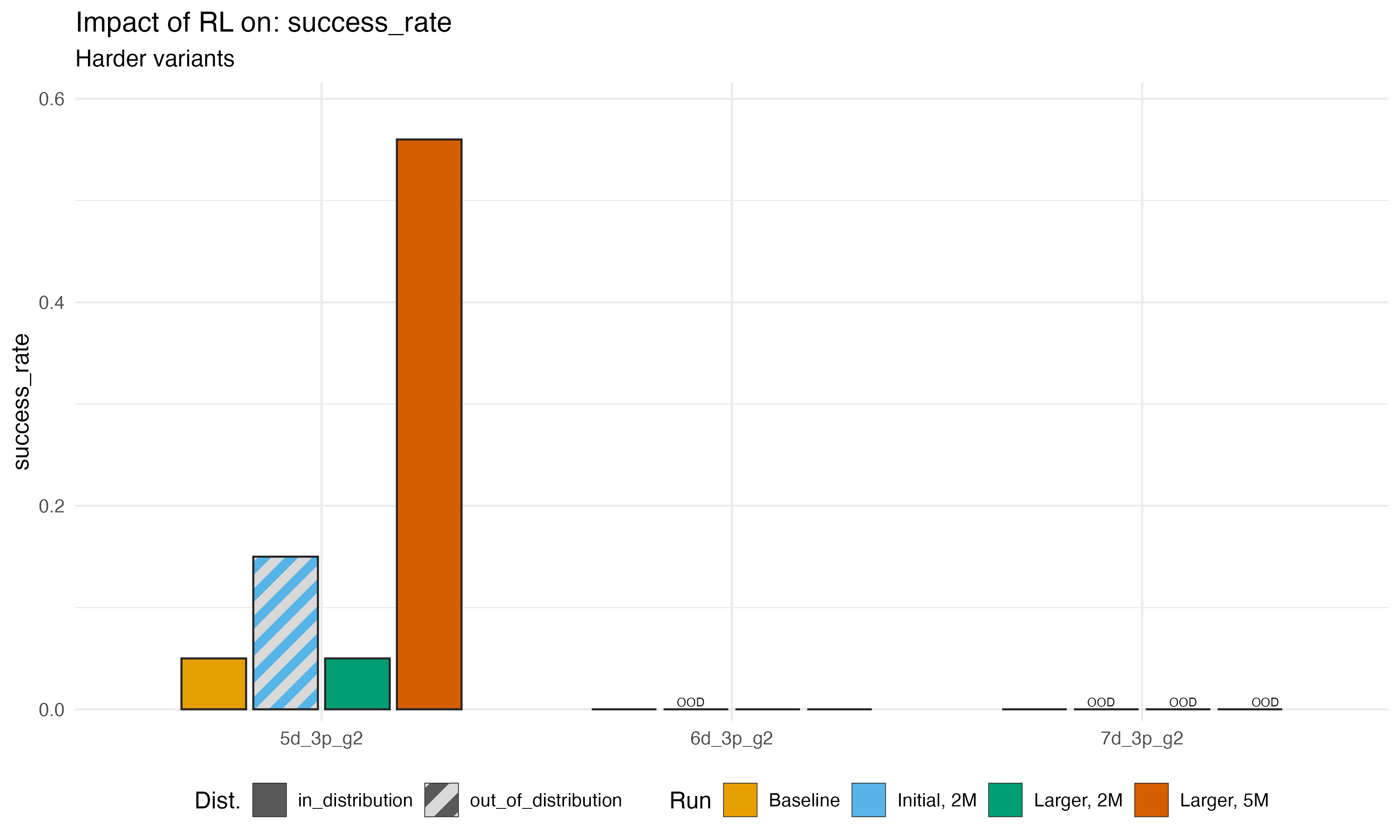
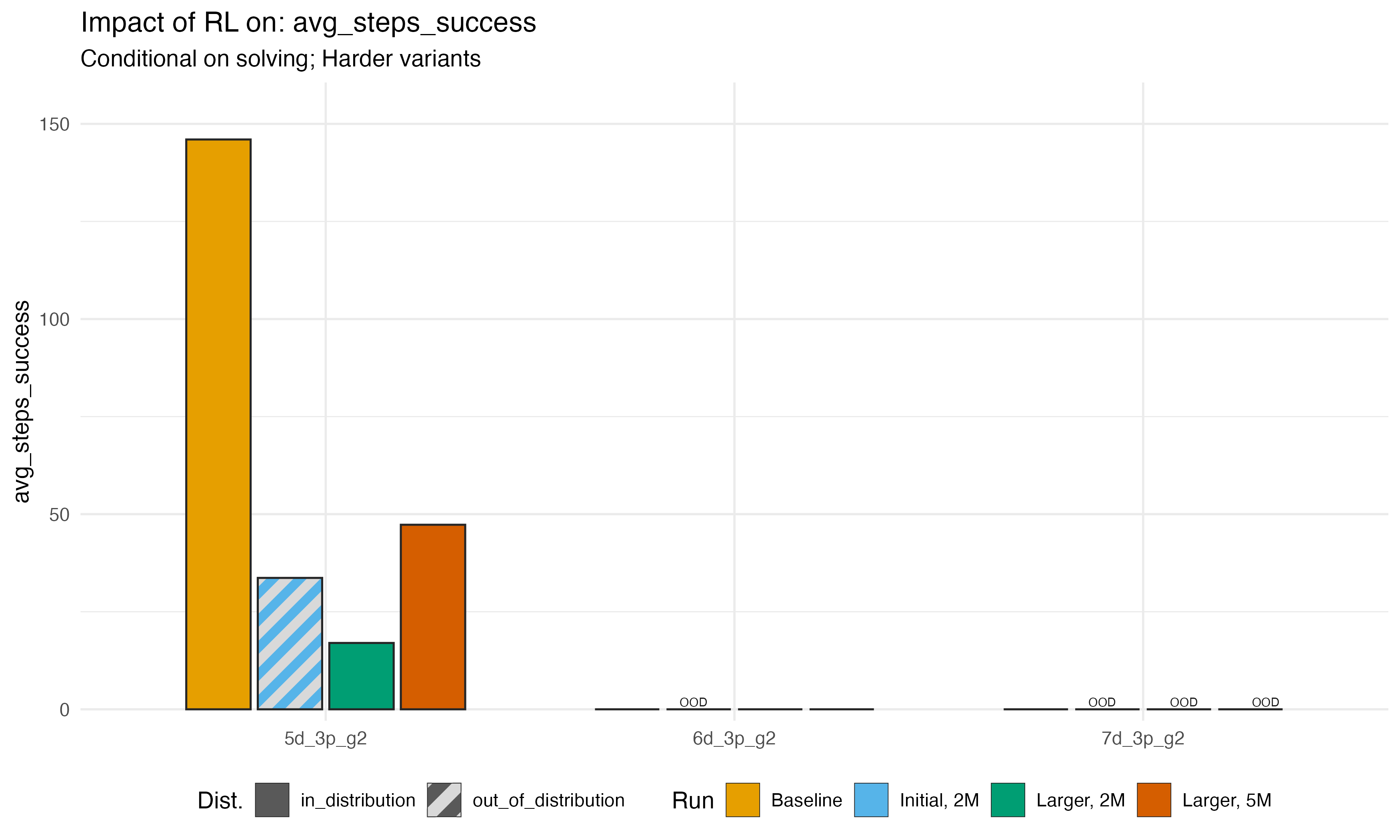
Finally, we can look at success rates and solution steps for the hard problems specifically. As we noted, the 5-disk problem was our glimmer of extrapolation in the first run, and we were able to improve performance on those problems further when we added them to training. We never, however, made any progress on 6- or 7- disk problems.
My takeaways
This post is already longer than I usually like to write, so I’ll condense my takeaways to bullets.
It was easier to teach an LLM something via RL than I realized. For simple game variants, the LLM started picking it up within minutes. I will definitely do more tests like this.
On the other hand, a bunch of compute was already spent to make this model. So the negative findings here are also surprisingly negative in my mind – a day on an A100 made the model forget how to solve problems it previously knew?
I learned a lot about how many RL training levers would need to be controlled at scale.
- How to combine easy and hard variants to speed learning
- Shifting the training distribution toward harder problems as easier ones are fully solved
- The cost of tracking evals over training runs at scale, to understand the learning process in detail. Every new mid-training eval costs time and compute, even for such easy problems.
- How much compute to spend meandering around hard problems – I set the maximum number of steps allowed at 300. For hard (5 disk and greater) problems, that might not be enough to find the solution. But increasing that number is quite costly too
RL is expensive. I’m sure I’m using compute inefficiently, but with 200-300 parallel workers and extremely condensed prompts on an A100 using a small, 5 million training steps cost me about $30 in GPU rental costs. I’m already a big believer in efficiency investments in the cloud/AI, but this made me even more so. I assume efficient RL is a big focus of labs right now.
Finally, I view this as a noisy but bearish signal for the extrapolation/“foom” story. Two related but separate points
- As tasks got harder, it took me dramatically more time to teach the LLM
- Training for a long time on easy problems was enough to get the LLM to solve other variants of easy problems, but not to solve harder problems.
Bonus: Some possible concerns and my responses
Finally, I can imagine some questions/critique people might have, and I have some basic responses
- Why set the temperature to zero? Higher temperature could have
allowed the LLM to stumble on better moves faster
- Answer: I felt like setting a higher temperature might have helped in this low-dimensional setting but would be less and less likely to help as the problem dimension scales. Moreover, even if we could stumble on the right strategy, that doesn’t seem like a particularly robust or efficient way to teach.
- These games are contrived. What about coding/math?
- Answer: Coding and math are way higher-dimensional and much harder settings in which to construct out of sample examples. Maybe models would do something that looks more like extrapolation there, but I also think it would be easier to deceive ourselves.
- Phi-series are explicitly tiny models – maybe this works better at
larger scale?
- Answer: Agreed that Phi models are small. But my success at easy problems says there are plenty of free parameters to learn them. So it’s not like we are bound by model size here. Making the model larger (or increasing the LoRA rank) could help learn more complex in-sample tasks but I don’t see why adding more parameters would help with the extrapolation component. If anything, it might mean we introduce more colinearity, as I doubt there is enough signal to estimate more weight updates.