Context Routing for Local LMs
Author: James Brand
Date: 2026-06-04
TL;DR Post about quality-speed trade-offs and repeated/predictable LLM tasks. For predictable questions, a cheap context-shortening model before inference speeds up inference by >50%.
Motivation
This will be a relatively short post. The idea is simple – in my recent post, I was trying to design the AI data science experience I want for myself, using Excel as a frontend and a simple agent equipped with a few R packages for lazy/SQL database functions for the backend.
One roadblock I hit there was that, to get the LLM to run fast enough, I had to route prompts to OpenAI’s API because my local Macbook Pro couldn’t handle any local LLMs quickly enough. So, that’s the whole question: can I speed up local inference to make the agent work faster without sending anything to remote APIs?
More broadly, what interests me lately about LLM inference has been the quality-speed trade-off for a fixed model. I.e., new model launches often draw Pareto frontiers of intelligence and speed, or token efficiency, across models, but one could imagine treating a model as fixed and asking: can I cut any corners in serving this model that improve speed a lot but only reduce quality slightly?
Ideas and Implementation
I tried a lot of options and ideas to find some speed here, via
Codex. One easy and purposefully naive pass I made was simply to ask
Codex to hunt through llama.cpp (which I’m using to serve
locally) for a inefficiencies I hypothesized. This was probably doomed
from the start given the number of eyes that have been on this code, and
indeed I failed. I also tried modifying the attention layers directly –
attention is very expensive for long contexts, so if we could modify an
existing model to skip some attention calculations for some prompts
(like a “sometimes sparse” attention), that would’ve helped. Here, I am
still optimistic about solutions but the llama.cpp
implementations of attention are quite efficient so it’d take me a lot
more time to figure out where and how to insert this logic. Preliminary
tests suggested that my hacks were brittle, and that even when they
worked, any kind of adaptive routing inside the forward pass cost too
much in additional compute.
The idea that ended up showing some promise was almost equally simple: when a user is having a long conversation, a lot of the preceding conversation is irrelevant for each turn. At least, that’s often true for me – e.g., maybe I start a chat asking about how to write a function in R, and then later I’m asking about a different function for the same project. The LLM doesn’t really need to know anything about the first request, but for the entire remainder of the chat (or until we hit context length limits) that request is passed along with everything else. In general chats, this would be really difficult to fix (presumably why we don’t see labs doing this, at least openly), but if we know something about the nature of the chat, then maybe we can learn a simple, cheap, model to filter out unnecessary context from each chat turn, thereby accelerating inference.
I’ve seen a few papers trying to do this kind of thing fully generically, and it seems difficult. E.g., Routing Transformers try to control which attention computations happen as a function of the context/prompt, which does reduce computation but don’t seem to have been adopted by labs at scale. Of course, even the mixture-of-experts architectures that are used by many near-frontier models are another approach at this which control which parameters are active instead. The broadest approach seems to be much simpler; every major AI tool I use has something like an “auto” mode in which the tool tries to route each request to different models depending on the amount of intelligence/“thinking” needed. This is both really intuitive and, from my experience as a user, really hard to get right.
My Excel agent seemed like a good use-case to try context shortening. Imagine you’re doing some data analysis and there are 10 tables in your Excel file. You might ask a question about a different table each request, meaning that previous requests can always be ignored. And what is useful is that, as long as a user is asking about the data in the Excel file, we have some helpful context (the schema of all available tables) to help us figure out how to re-write/shorten the context to the relevant pieces.
Implementation
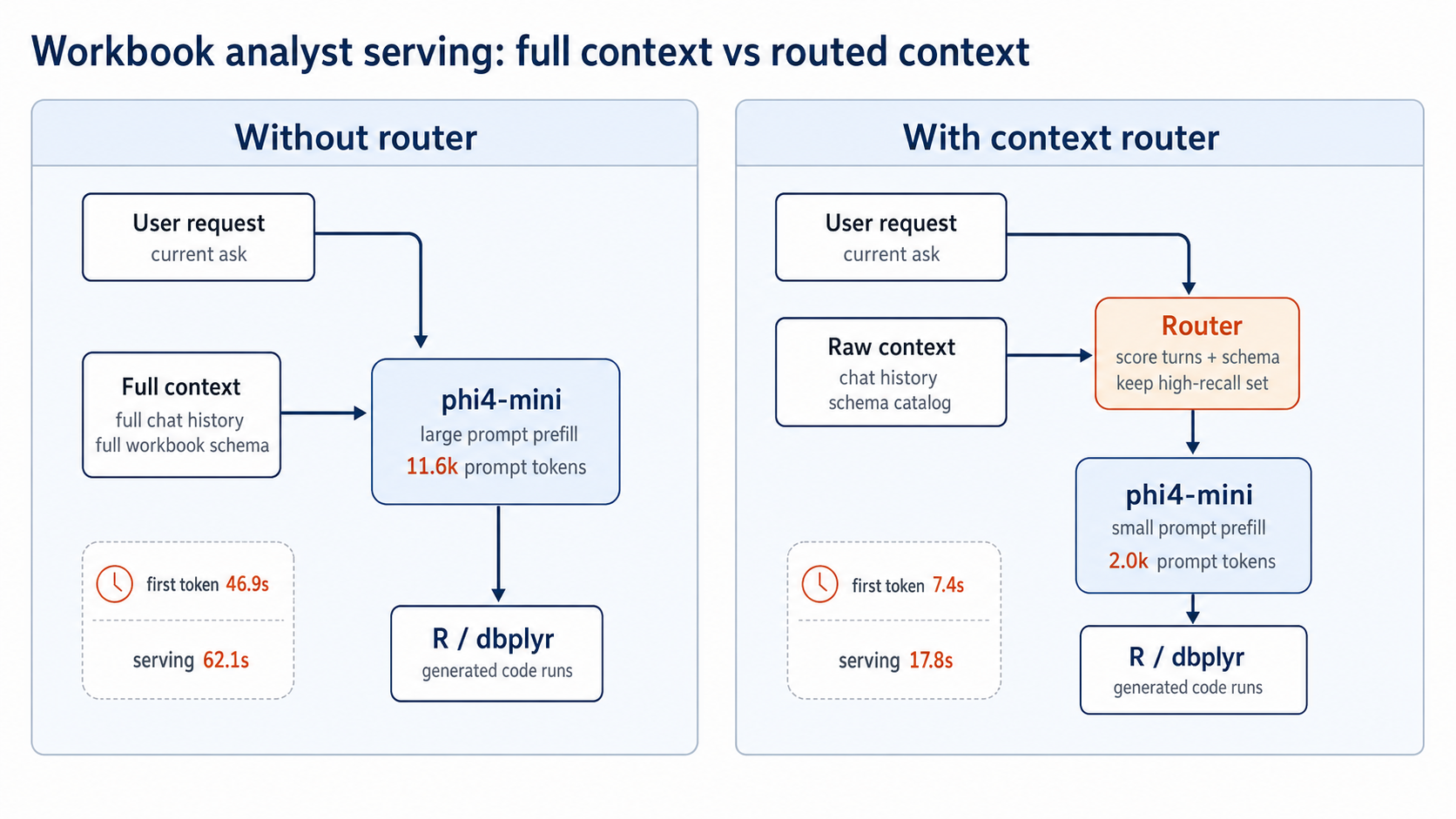
This idea took a surprising number of tokens to get working, but I’m really happy with the simplicity of the resulting process. I made some spec images below, courtesy of Codex image gen. The first, below, shows how my ``router” inserts into the inference process. The user passes the full chat, the tokens from which are then scored by the router for relevance, and then we return the tokens with the highest scores.
Zooming in a little deeper, the first version of this router can be
quite simple (as shown below). The whole idea behind the agents I want
working for me is that I want to know the (limited) set of tools they
have available to them. As a nice consequence, when the chat says
“regression,” we can guess that that’ll refer to a chat turn in which
dbreg was used, as that’s the only regression tool
available. As a result, we can shrink to those chats that use that term
in a tool call specifically. In short we are trying to drop, as simply
as possible, any chat turns that feel unlikely to help the agent.
Obviously this could become more complex in production settings via a
learned model: 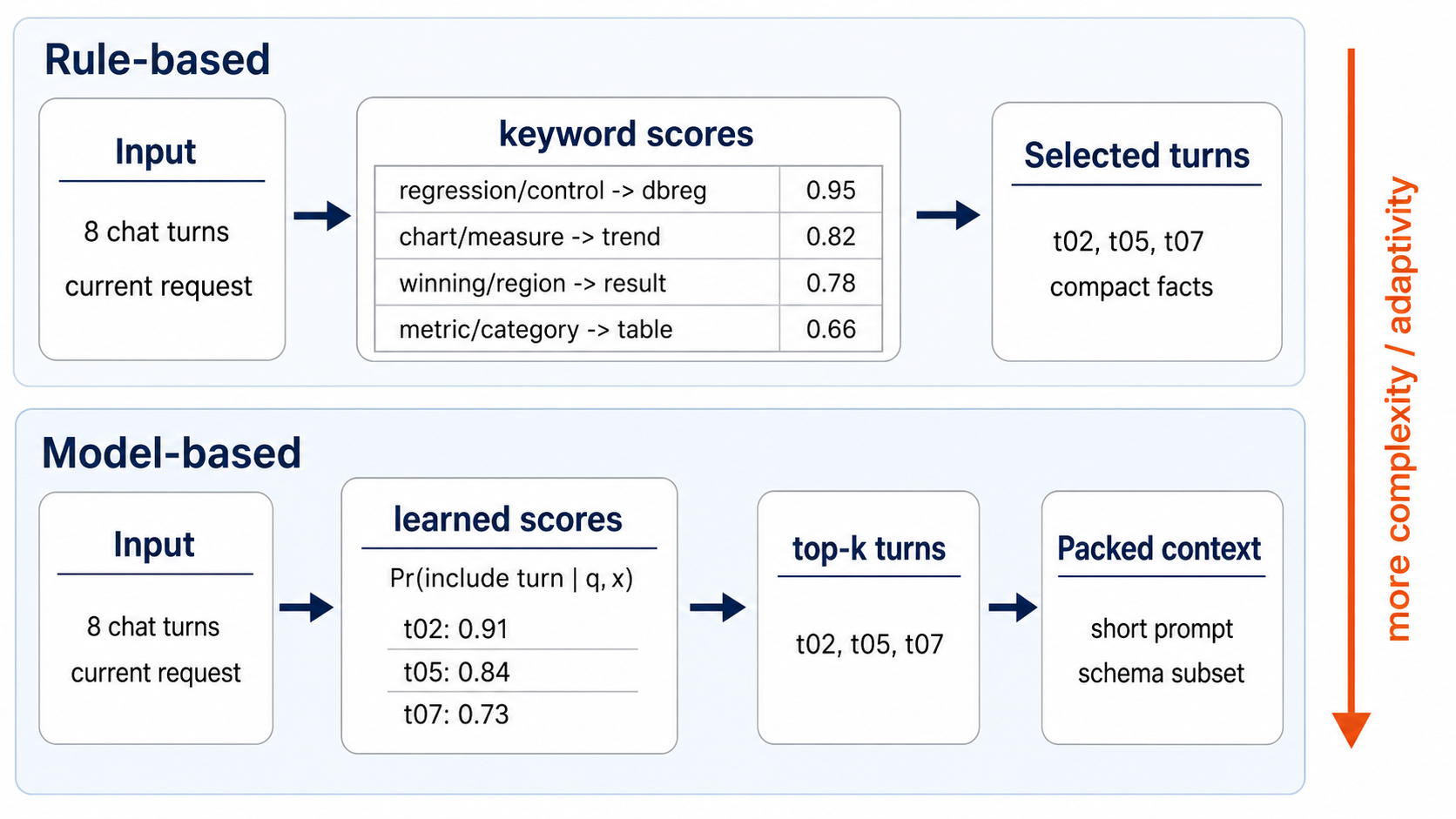
Performance
As in my last post, to show the performance of this idea I had Codex rig up a screen recording. This time, the goal is to show that with the same chat history, the simple rule-based routing model above correctly identifies that some recent chat responses are irrelevant and excludes them from context, accelerating inference. In case it’s hard to see in the video, what is shown here is a stting in which a 6-turn chat has included multiple different linear regression requests. Then, the latest turn refers back to one of those regressions and asks for an extension
Scaling?
One simple example is easy to cook up, but obviously the risk of this approach is that we accidentally chop off part of the context that really mattered to the user. My read of the current market for frontier intelligence is that there’s enough compute out there, and enough competition on accuracy specifically, to make this an impossible trade for companies to make in their main products. But for individual devs fitting LLMs into repeated workflows, I suspect a good rule-based + statistical model can keep failures pretty rare for some tasks.
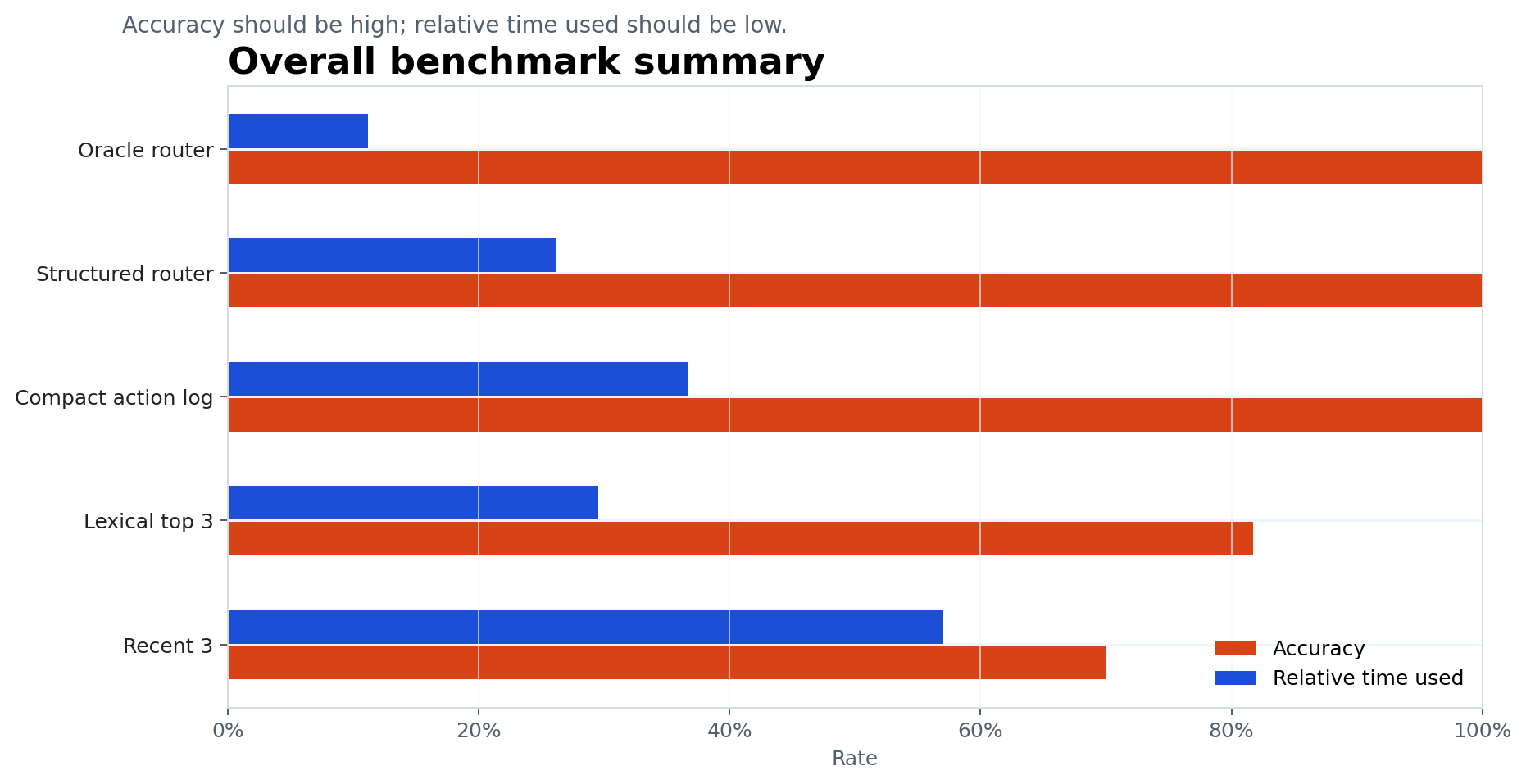
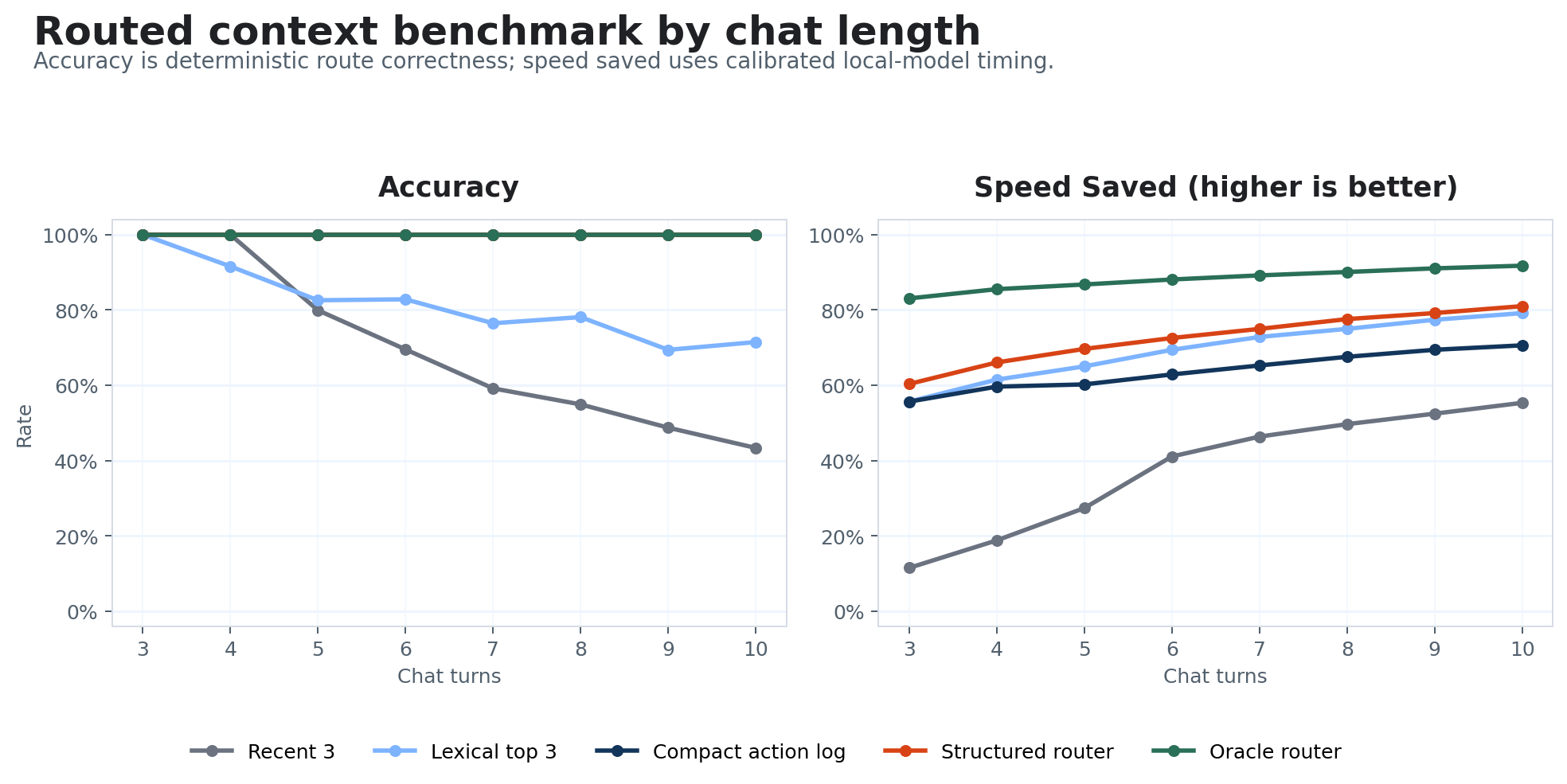
Since this is a vibe-coding post, we might as well let Codex cook up a much broader set of chats/contexts and different routing approaches, to compare accuracy and timing trade-offs. I tried a few routers:
- “oracle”: not really an oracle, but keeping exactly the minimal referenced chat turns as context
- “structured”: keyword matching rules with fallback to full context as needed
- “compact action log”: keep all previous turns, but only the tool/action calls from the LLM
- “Lexical top 3”: count the number of shared tokens between current request and previous turns, keep top 3
- “Recent top 3”: 3 most recent turns
We (Codex and I) then applied each router to 2,000 synthetic chats, each of which his 3-10 turns in contexts with 3-10 tables, where each table has 12 columns and chats have both multiple questions and some irrelevant/distractor questions inserted. See a few graphs below summarizing performance. In short, adding more tables to the context doesn’t cause any problem for the more verbose routers; adding more turns definitely makes the problem harder but some simple rules catch a lot.
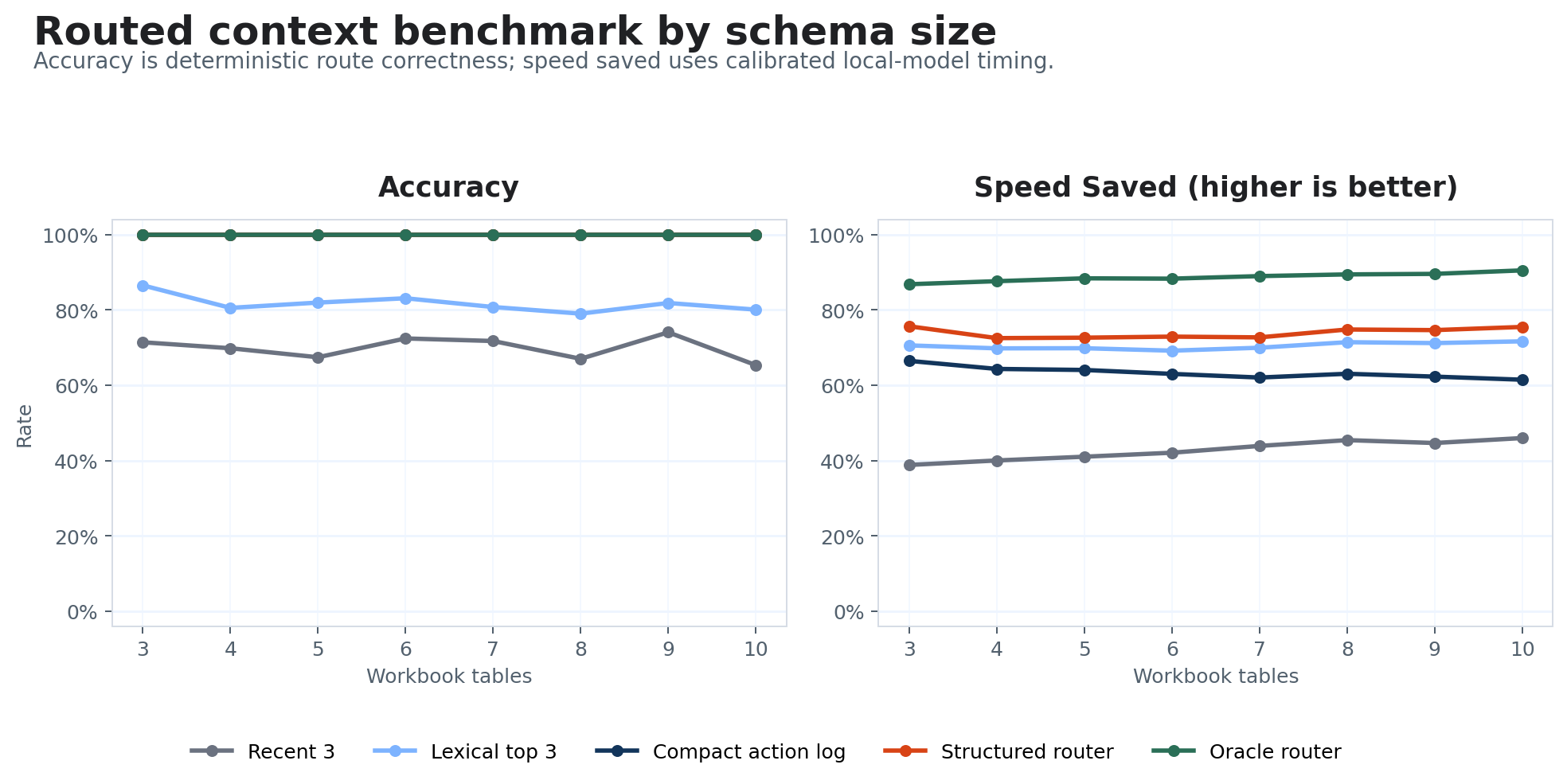
This is my first attempt to do anything with LLM inference – I know it’s simple, but I learned a lot and expect to post more about other attempts at learning-by-doing with LLMs.