Open-source demand estimation
Author: James Brand
Date: 2025-05-30
This is my first post here so I have to sell my own book – specifically open-source demand estimation, which I now have 3 “packages” for:
NPDemand: Quasi-bayes nonparametric demand estimation from Brand and Smith (2024). This estimates the inverse demand curve flexibly, then inverts that estimated function to calculate price elasticities.
FRACDemand: “Fast, Robust and Approximately Correct” demand estimation from Salanie and Wolak (2022) (who changed the name of their method after I was committed to the name “FRAC”). This estimates a mixed logit model as a Taylor expansion around a pure logit model. This introduces approximation error into the estimates but speeds estimation by >100x relative to BLP.
FKRBDemand: Demand estiamtion with nonparametric random coefficients, from Fox, Kim, Ryan, and Bajari (2011). This estimates a mixed logit model by specifying a grid of preferences, then estimating weights on that grid via an elastic net regression. In my implementation, this grid is set adaptively using a first step
FRACDemandproblem.
All three use data at the market-product-time level. NPDemand is
pretty functional now, since it’s the foundation of a working paper, and
we’re actively building in new features that will speed it up a lot. I
don’t spend near enough time working on FRAC and FKRB to make them great
as quickly as I’d like, but they should work reasonably consistently if
you handle the inputs as I’ve done in the examples. The latter two are
now registered (meaning you can Pkg.add() them!) and I’m
putting together a short paper to demonstrate their capabilities more
fully and will post it here when it’s ready.
Why I want people to get excited about these approaches/packages
A lot of Matlab/Julia/Python is spilt every year writing custom code to get even very preliminary estimates of structural demand models. I’ve talked to people who take 6 months (easily) to code up the estimation, elasticities, and counterfactuals. Two things about this are clearly suboptimal:
- We have a lot of uncertainty over model specification (e.g., number
of fixed effects, random coefficients)
- A subpoint is that mixed logit models are amazingly flexible, meaning a lot can be hacked into them without moving outside of that framework
- A lot of structural code is duplicating work that 1,000 people have already done
On the first point – in any realistic setting, there is a ton of uncertainty around how to specify a structural model. How many product characteristics should have random coefficients? How many fixed effects should we include? What about nonlinearities in the utility function? Even ignoring the scary researcher degress of freedom here, this simply takes a ton of time to explore. Researchers will estimate one model, then realize they want one or more fixed effects, or they want random coefficients to take on a different distribution, or some other multi-week delay testing and fixing the bugs that arise because economists are not trained to be good software engineers. As much as I think McFadden and Train is over-hyped, it does point out that if we had one really good “mixed logit estimation machine” we could approximate a lot of messy DGPs. Some dynamic models could be approximated with lags, nested logits can be approximated with random coefficients on group fixed effects (this is probably the better thing to do anyway), and so on – I’m guessing that more clever people would have more ideas here if this type of creativity was valued.
On the second point, structural economists are way behind the times in terms of replicability of results. Part of this is a software issue, and part is cultural. How many applied economists have ever written algorithms for high dimensional fixed effects? Less than 10 (20, tops?) I suspect. In contrast, 99% of IO economists have had to write custom code to estimate BLP at some point. Worse, they’ve probably even written custom code for the required GMM process under the hood. What’s the point of that? While there is definitely value here to some economists knowing the algorithmic details of these methods, in practice most people who need to implement these methods really do not need to know all such details, and I think they often don’t learn them anyway! So the result is that there are hundreds of economists who estimate the same models but have no shared code to easily replicate, test, and expand on each others’ work.
I’ve purposefully tried to increase the number of packages/methods I’m covering faster than I polish any specific package to perfection – partly because there are so few users that polishing is low ROI, and partly because I really want people to get used to seeing a simple, unified, API to defining, estimating, and processing structural demand models, to fix some of these problems above. I learned this from PyBLP, of course, though I’m partial to my own structure here. Here’s what I mean by a shared API:
frac = FRACDemand.problem(
data = df,
linear = ["prices", "x"], # characteristics in the utility function
nonlinear = ["prices", "x"] # which characteristics should have random coefficients
)
fkrb = FKRBDemand.problem(
data = df,
linear = ["prices", "x"],
nonlinear = ["prices", "x"],
constraints = [:nonnegativity, :proper_weights]
)
nonparametric = NPDemand.problem(
data = df,
index_vars = ["prices", "x"], # characteristics in the utility function
constraints = [:monotone, :diagonal_dominance_all, :all_substitutes],
quasibayes = true # whether to use quasi-bayes estimation or GMM
)Now the same data can be passed into multiple similar functions to estimate different specifications, with very little custom coding. Certainly the way I would now approach demand estimation in an empirical paper would be to push these packages to their limits before writing any custom code.
How well do they work right now?
As I mentioned above, I’m working on a draft to show this at better scale, but in my view these methods are massively underused relative to their accuracy and speed. In many cases, I think estimating a flexible version of these models is going to outperform a more complicated model once you account for the coding time and uncertainty in the latter.
Two quick figures to show how nicely these packages seem to work. First, a plot of FRACDemand estimates of the variance of preferences for prices in a simulated example I cooked up. The details don’t matter a ton – what is important is that the only code required for each simulated estimate I run is:
problem = define_problem(data = df,
linear = ["prices", "x"],
nonlinear = ["prices", "x"],
fixed_effects = ["market_ids"],
se_type = "bootstrap",
constrained = true);
estimate!(problem)
bootstrap!(problem; nboot = nboot, approximate = false)The bootstrap! function uses the FRAC results to invert
the demand function for demand shifters, then calculates
nboot bootstrap results to debias the estimates. This is
useful because basic FRAC estimates of preference variances are going to
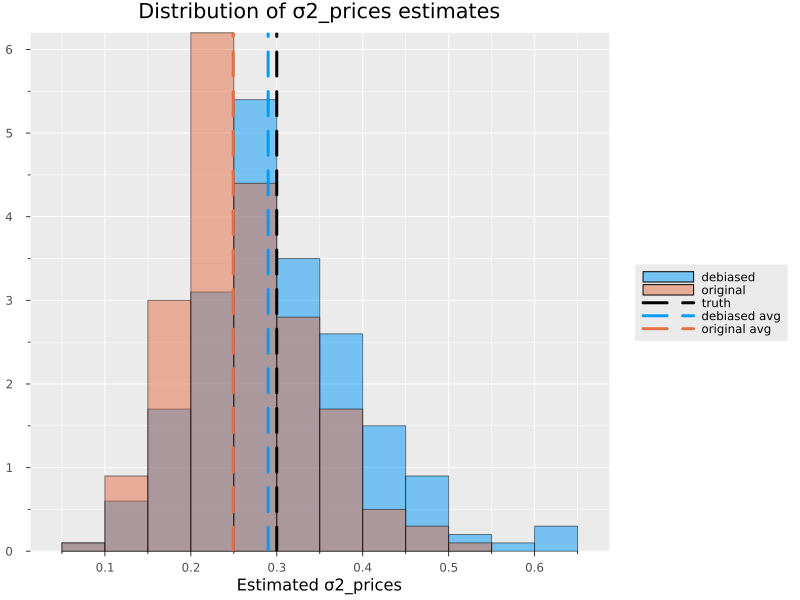
be biased (down, in my limited experience). The graph below shows that
debiasing basically works – over 200 simulations, debiased estimates are
much closer to the truth (close enough that the impact on estimated
elasticities is very small). Even without debiasing, the estimates
aren’t useless by any means.
If you’ve estimated a structural model before, then the second best thing here (the first being the brevity of the code) is that estimation and 30 bootstrap samples takes 12 seconds. The biggest time cost is the contraction mapping, which only has to run once. So if you wanted to test 20 different models of utility here, without debiasing or inference, those results would take at most a couple of seconds to run. This is the benefit of keeping structual modeling in the world of linear regression, and out of MLE and nonlinear GMM whenever possible.
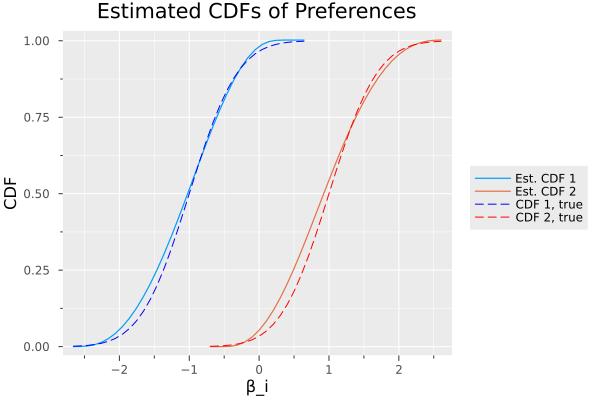
We can look briefly at FKRB’s speed and accuracy too. The method I’m implementing for FKRB is actually a hybrid FRAC-FKRB approach, which was motivated by Meeker and von Ditfurth and expanded on in my previous post. So what happens is that we estimate a FRAC problem, then use the results to define an estimation grid for an FKRB problem.
problem = FKRBDemand.define_problem(
data = df,
linear = ["prices", "x"],
nonlinear = ["prices", "x"],
fixed_effects = ["product_ids"],
alpha = 0.001, # grid will attempt to cover 1-alpha of the preference distribution
step = 0.1 # grid step size
);
# One-line estimation
FKRBDemand.estimate!(problem,
method = "elasticnet",
constraints = [:nonnegativity, :proper_weights], # enforce non-negative weights that sum to 1
gamma = 0.0, # L1 penalty in elastic net
lambda = 0.0) # L2 penaltyJust like in the FRACDemand example, we nail the distribution of random coefficients, without any distributional assumptions on those coeffients and allowing for the price endogeneity IO folks are often worried about. In this case (because the regressions are slightly larger) it takes 3-5 seconds to estimate this distribution.
Final thoughts
I’m definitely not saying these methods are perfect and one-size-fits-all. Nor am I saying that structural modeling isn’t valuable (a perspective I hear too often from tech economists/data scientists). The structural interpretation of these models is key to actually utilizing the results in internally consistent ways. What I am saying is that I think the estimation of structural models should be rethought. I think the IO academic field is stuck in a rut, where we produce very complex papers and models and do not place nearly enough emphasis on creating re-usable tools.
Arpit Gupta has made the point repeatedly (though I can’t find the tweets at the moment) that, whereas ML, A/B testing, and even sometimes observational causal inference, have been pretty broadly adopted by tech companies, structural work is way less penetrated. In my experience, log-log regressions dominate for demand estimation, because it’s a one-liner to write and interpret, even if it’s also really restrictive and harder to interpret within a coherent choice model. The software gap plays a big role in this, and I’m hopeful that others will be convinced by my frequent posts to this effect and create better tools than I’m able to.
P.S.: Recent updates to FRACDemand and FKRBDemand
These packages, because I haven’t convinced people to use them, remain a very small side project of mine (other than NPDemand, which is much more complete). Every once in a while I get a spurt of energy to work on them though, so I wanted to mention some of the changes I’ve made recently and some of the things I want to do in the future.
FRACDemand.jl
- The package is now registered, so you can install it with
] add FRACDemand. - Now includes generic correlated random coefficients in the unconstrained version of the problem
- Starting to add some long overdue documentation and tests, though both are still pretty sparse
- Next: Speed improvements for counterfactual prediction and elasticities. Also hoping to incorporate correlated RCs into the constrained version of the problem.
FKRBDemand.jl
- Just registered, so you can install it with
] add FKRBDemandnow. - Improved plotting functions to analyze estimated preference distribution